Défaut: Architecture CoSQL Métadataware métastabilité Meijer programmation
by Christian
19 comments
Sens et enjeux des modèles de stockage et d’accès aux données
C’est typiquement le genre d’article qui nécessite des corrections, des remarques et peut-être un débat. Alors n’hésitez pas.

Code et data
Pas de code sans données, car le but d’un code est de tourner et de produire des résultats et, pour ce faire, le code doit “manger” des données.
On peut voir le code dans sa forme la plus abstraite comme un algorithme dont le rôle serait de produire des preuves. Mais on peut aussi voir le code comme un algorithme qui ne fait pas simplement que valider et prouver mais également qui produit des changements d’états et des évènements qui, au sens littéral du terme, changent le monde.
On a ici un parallèle avec les “speech acts” de Searle et Austin dont Henry Story avait parlé dans son intervention au MeetUp Semantic Web de Février 2011.
Quiconque écrit un programme s’attend en effet à “changer le monde”, ne serait-ce que pour écrire “Hello World” sur un terminal. Changer le monde avec des algorithmes et du code, Microsoft, Google, Facebook et d’autres l’on fait, et l’ensemble des développements en Open Source peut-être plus encore.
Pas de code sans données donc. Or ces données sont stockées dans des supports de mémoires différents selon qu’elles sont en mémoire vive, sur un système de fichier, ou dans une base de donnée. Et chaque support de mémoire utilise un modèle de données qui n’est pas forcément le même. Ce qui nous ramène à la difficile collaboration entre les développeurs et les gestionnaires de base de données.
Si les développeurs et les administrateurs de base de données doivent collaborer, la réalité est parfois toute autre : les développeurs ne comprennent pas toujours le SQL et les RDB (bases de données relationnelles), et les DBA (administrateurs de base de données) ne voient les développeurs que comme de dangereux cowboys qui veulent massacrer l’intégrité de leur données (“mon précieux …”).

Le DBA

Le développeur
“Impedance mismatch”
La réalité est que les modèles de données utilisés dans les langages développement et dans les systèmes de stockage des données ne sont pas les mêmes : modèle objet et modèle tableau.
C’est ce qu’écrivait Yves-Marie Pondaven, que je citais également dans mon intervention au MeetUp Semantic Web de Décembre 2010, et dont je reproduis ci-après le schéma qu’il avait fait et dans lequel on voit que l’on passe son temps à basculer du modèle relationnel au modèle objet puis au modèle document et inversement.
Aussi disais-je que la plupart des CPUs de la planète sont occupés à faire des transformation et re-transformation entre des modèles de données différents. On peut donc au moins dire que cela a un impact en terme de performance mais aussi en terme environnemental non négligeable (de l’ordre de l’impact carbone sur la planète de toute l’industrie du transport aérien).
Cette question des différences entre les modèles de données n’est pas nouvelle, et elle a d’ailleurs fait l’objet d’une discussion intéressante entre Michel Volle et Laurent Bloch. Plus généralement, elle fait référence à “l’impedance mismatch” de George Copeland & David Maier 1984:

The problem with having two languages is“impedance mismatch ” One mismatch is conceptual – the data language and the programming languages might support widely different programming paradigms. […]
The other mismatch is structural -thelanguages don’t support the same data types, […]
Objets versus Tables
Avec les travaux d’Erik Meijer, de chez Microsoft Research, on peut essayer d’aller plus loin dans l’analyse de la situation, et je vais suivre à présent son argumentation, telle qu’il a exposé lors du WebWorkers Camp parisien du 16 avril 2011, et en faisant référence au papier qu’il a publié en Mars 2011 : A co-Relational Model of Data for Large Shared Data Banks.
L’objet-graphe et le stockage par clé/valeur (Key/Value)
Tout commence par une citation de Donald Knuth :
“I do consider assignment statements and pointer variables to be among computer science’s most valuable treasures.”
Pourquoi Meijer souligne-t-il ainsi l’importance des pointeurs pour ensuite assimiler l’équivalence entre le modèle objet et le stockage par clé-valeur ? :
“In the rest of this article we conveniently confuse the words object (graph) and key-value store.”
Deux choses ici :
- D’une part, l’équivalence entre objet et graphe.
- D’autre part, l’assimilation du modèle objet au mécanismes de stockage par clé-valeur.
Si l’objet est assimilé à un graphe c’est parce qu’une des caractéristiques de l’objet est d’avoir la structure d’un graphe, à savoir que les objets sont reliés entre eux par des relations qui, en l’occurence, sont dirigées (d’où la flèche) :

Référons-nous à wikipedia (article sur Object Graph) pour comprendre l’assimilation de l’objet-graphe à un mécanisme de stockage des données clé-valeur :
“An object graph is a directed graph, which might be cyclic. When stored in RAM, objects occupy different segments of the memory with their attributes and function table, while relationships are represented by pointers or a different type of global handler in higher-level languages.”
Un Objet est donc stocké en mémoire en encapsulant avec lui avec tout ce qui le caractérise (attributs et fonctions). Si cet objet-graphe est stocké dans différentes parties – ou segments – de la mémoire, les relations entre ces différentes parties, elles, sont représentés par des pointeurs (ou par des mécanismes plus généraux embarqués dans les langages de plus haut niveaux). Les pointeurs étant des types de données dont la valeur est l’adresse vers un autre objet stocké en mémoire.
Paradoxalement, le concept de pointeur rebute souvent les étudiants en informatique alors que l’architecture du web qu’ils utilisent tous les jours en est exactement la mise en oeuvre avec des ressources stockées qui sont accessibles via des relations qui sont représentées par des adresses, les URLs.
Voilà donc pour le côté “stockage en mémoire” des objets manipulés par les programmes. Basiquement, il s’agit d’un mode de stockage de type Key -Value qui représente une part importante de l’utilisation des bases NoSQL et sur lequel, je l’ai dit, repose l’architecture du web (de là à justifier le NoSQL comme mouvement surdéterminé par l’architecture du web, comme son milieu technologique d’émergence, il n’a qu’un pas).
Le stockage de données par tables
Passons maintenant au modèle utilisé par les bases de données relationnelles, représenté non plus par des objets mais par des tables.
Par rapport au modèle objet, la table va fractionner les données pour les lier d’une manière différente du modèle avec pointeur utilisé pour l’objet-graphe.
Alors que la manipulation des donnés en mémoire sous forme de graphe était au plus proche de leur mode de stockage physique en RAM, le modèle relationnel va “plaquer” un mode de stockage et de requêtage qui repose sur le modèle des tables. D’ailleurs, la première chose que l’on fait pour créer une base de données c’est d’écrire :
CREATE TABLE.
Ici il n’y a plus seulement une adresse pour une valeur (Key-Value), mais une valeur ( la primary key) dans plusieurs lignes. C’est la raison pour laquelle le modèle relationnel est aussi appelé Primary/Foreign Key.
Les contournements du modèle relationnel
Le modèle relationnel n’est pas évident dans sa compréhension et dans son utilisation. Meijer souligne tout cela par un raccourcit ironique :
- Le concepteur de base de données enlève la structure originairement hiérarchique et objet pour lui appliquer un modèle normalisé par Tables ;
- Le développeur doit ensuite retrouver la forme objet-graphe originale pour son développement. On a ainsi eu une vague d’ORM (Mapping Objet/Relationnel) qui, comme leur nom l’indique ajoutent une sur-couche objet au modèle relationnel afin que le programmeur puisse utiliser le stockage relationnel sans en connaître toutes les subtilités ;
- Même du côté de la base de données, celui qui l’implémente doit rajouter une couche de stockage objet-graphe et Clé-Valeur en construisant un index de la base de données, en marge du modèle par Tables, pour pré-calculer des réponses à des requêtes.
A croire que, dès qu’on veut utiliser les bases de données relationnelles, il faille changer de modèle de données pour en revenir au modèle objet-graphe et le stockage par Clé-Valeur.
Sortir de l’aporie
Jusqu’ici rien de bien nouveau dans le “dysfonctionnement relatif” entre modèle Objet et modèle Relationnel, si ce n’est la montée en puissance des base NoSQL. Mais celles-ci n’ont pas vraiment de modèle de requêtage très élaboré (pas de modèle mathématique) : en effet il y a plutôt des recettes de requêtage dans le monde NoSQL.
Là où Meijer est intéressant, c’est dans la manière dont il formule le problème pour dépasser la vision d’opposition entre SQL et NoSQL. De la logique d’opposition on bascule alors dans une logique de composition, et les choses deviennent beaucoup plus claires.
Meijer, tel Ménon, fait son petit schéma (fig. 6 pour le modèle objet, et fig.7 pour le modèle en tables) et constate que :
- le modèle objet est défini par intension
- le modèle table est défini par extension.
- et surtout, on voit bien sur le schéma que le sens des flèches est inversé.


Je rappelle brièvement qu’une définition par intension décrit la liste des propriétés qui doivent être vérifiées pour qu’un élément appartienne à l’ensemble ainsi défini. Dans la définition par extension c’est la liste des éléments qui définit l’identité de l’ensemble :
“Toute classe d’éléments peut être définie en extension (en nommant ou en désignant chaque individu qui en fait partie) ou en intension, par une description (spécification d’un certain nombre de prédicats) qui définit la classe. L’intension s’identifie ainsi au concept. »
Par exemple, la classe des rois de France peut être désigné extensionnellement en donnant une liste de noms, ou intensionnellement par le concept « roi de France » (c’est-à-dire le prédicat, la propriété « être un roi de France »).” Intension et Extension, Wikipedia.
En informatique, toute donnée doit être porteuse d’une identité qui la distingue de toute autre donnée. Toute donnée, c’est à dire toute information disponible pour un calcul, doit disposer d’une identité. Et celle-ci passe par un référent (par exemple un identifiant), qui n’est autre qu’une métadonnée (Cf. Sur les métadonnées).
Il se trouve qu’avec le modèle objet-graphe, la métadonnée qui sert de référent pour l’identité de l’objet n’est pas une valeur mais l’adresse d’une valeur (le pointeur). Alors qu’avec le modèle en Tables, la métadonnée est une valeur (c’est la clé primaire).
La métadonnée qui sert de référent peut donc être définie par intension ou part extension :
- par intension, on a une clé qui est une adresse
- par extension, on a une valeur (clé primaire) qui est présente dans toutes les lignes des tables qui constituent l’identité de l’objet.
On comprend aisément la forte contrainte d’intégrité requise pour les bases de données relationnelles : une modification doit se déployer sur l’ensemble du système, de manière extensive, pour en garantir l’intégrité. Avantage à la maîtrise des données mais difficultés à passer à l’échelle du web.
Mais avec son petit schéma, Meijer, remarque que le modèle Objet et le modèle Table sont fort similaires : ce sont des graphes orientés, mais avec une orientation inverse :
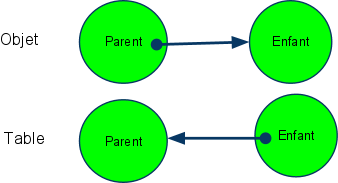
Ne manque plus qu’à Erik Meijer de chercher “Mathematics arrow reverse” dans Google pour tomber sur la page Wikipedia de la théorie mathématique des catégories.
Théorie mathématique des catégories et le concept de dualité : “NoSQL is CoSQL”
De la théorie mathématique des catégories, Meijer retient le concept de dualité, ou catégorie duale :
À partir d’une catégorie
opposée ou duale, en prenant les mêmes objets, mais en inversant le sens des flèches.
Plus précisément :
Il est clair que la catégorie duale de la catégorie duale est la catégorie de départ :
Cette dualisation extrêmement simple permet de symétriser la plupart des énoncés, ce qui peut être douloureux pour les débutants…





Ce “détour” par les mathématiques permet finalement à Meijer d’affirmer que :
- SQL et NoSQL ne sont pas incommensurables et incompatibles ;
- NoSQL s’appuie en fait sur un modèle de donnée qui reléve d’une catégorie duale où l’on a les mêmes objets mais en inversant le sens des flèches ;
- Donc NoSQL est en fait CoSQL ;
- A partir de là, on peut fonder les modes de requêtes NoSQL sur une théorie mathématique, comme s’était le cas pour SQL, ce qui permettra non seulement de standardiser les requêtes pour différentes bases NoSQL mais aussi de fonctionner pour les bases SQL.
Le rôle d’une interface est précisément de faire cohabiter des modèles différents, qui ne sont certes pas opposé et incompatibles sans quoi l’existence même d’interface ne saurait être possible.
Avec son langage de requêtage “universel” LINK, Meijer ne fait rien d’autre que d’avoir trouvé, via le recours aux théories mathématiques, une interface entre des modèles qui étaient présentés comme apparemment opposés. L’interface est à ce tire une composition.
Bien qu’étant universel sur le papier, LINK reste toutefois implémenté dans le monde .NET. Il faudrait donc une implémentation de cette démarche pour chaque langage pour parler vraiment d’un langage de requête universel.
Langage fonctionnels purs et monades
On connaît l’implication de Meijer dans la valorisation, la promotion des langages fonctionnels et notamment de Haskell (je vous renvoie à mon article Apprendre Haskell dans lequel je donnais les liens vers les tutoriels video de Meijer sur Haskell).
En fait, l’approche qu’il a implémenté avec LINK lui a été soufflé par les monades en Haskell. Pourquoi celà ?
Rendre compatible ce qui est incompatible est précisément le rôle des monades en Haskell. Puisque le langage est pur et fonctionnel (aucun effet de bord et immutabilité) il ne peut interagir avec le monde et le changer, il faut définir un lieu d’où les effets de bord (comme l’impression sur un terminal) seront quand même possibles.
Les effets de bord sont souvent dûs à des erreurs du point de vue des Types des données manipulés. Par exemple la fonction qui affiche l’heure n’est pas pure car à chaque fois qu’on demande la valeur, la fonction produit un résultat différent (l’heure tourne). Donc, un travail sur le Type System peut contourner la difficulté en considérant que la fonction ne revoie pas un INT mais un CHAR : on a contourné l’effet de bord en maîtrisant la définition par intension de la fonction dans la configuration des types.
Pour bien comprendre l’intérêt de cette question, on peut y retrouver un usage dans les architectures RESTful. Ainsi « Idempotence » en REST signifie « Pureté » en langage fonctionnel : la valeur d’une fonction ne change pas dans le temps (pas d’effet de bord). Par où l’on voit que le style d’architecture REST est un style qui s’appuie sur une architecture fonctionnelle pure par défaut : POST n’est pas une fonction idempotente (pure) car elle va modifier l’état du système.
Mais toute approche fonctionnelle pure doit composer avec le non-pur. Les programmes sont faits pour changer les états de systèmes et pour changer le monde. Les monades sont faîtes pour effectuer cette composition en créant des Types qui vont décrire ces effets de bord (IO, Exception, Animation, Collection). Les exceptions sont intégrées et gérées par le système qui conserve ainsi sa pureté grâce à son Type System (il n’y a pas que Haskell qui utilise cette approche par monades, Java aussi avec “throws Exceptions”).
Les monades transforment ce qui est mutable en quelque chose d’immutable (mutable et immutable étant les termes informatiques anglais utilisés).
En fait, je me demande si la modification que l’on fait avec les monades ne consisterait pas à définir de nouveaux Types non plus par intension mais par extension.
SQL et CoSQL à la lumière du concept de métastabilité.
Meijer rapproche l’articulation, qui est composition, entre SQL et NoSQL à celle du Ying et du Yang chinois, l’un désignant l’ouvert et l’autre le fermé. Puis il expose la dualité, au sens mathématique du terme, entre SQL et CoSQL, entre le fermé et l’ouvert :

On reconnaît dans cette distinction celle que j’avais essayé de faire entre technologies de gestion et technologies relationnelles, c’est à dire entre stabilité et métastabilité (Cf. Les technologies relationnelles dans les systèmes d’information et Métastabilité et archtitectures logicielles )
Le sens des flèches : des flèches du web au PageRank de l’index de Google.
Ouverture et métastabilité du web.
J’ai déjà rappelé l’anecdote à propos de Tim Berners Lee qui n’avait pas trouvé d’investisseur lors du Symposium sur les systèmes hypertextes en venant présenter son invention : le web.
Ceux qui pensaient en matière de technologies de gestion et de système clos et stable ne comprenaient pas l’intérêt d’un système métastable comme le web qui ne garantissait pas l’intégrité du système. Par exemple on peut faire des liens vers des ressources qui n’existent pas et provoquer une erreur. Seulement voilà, cet effet de bord est prévu dans le web, c’est précisément l’erreur 404 que connaît et intègre le système (utilisation du principe de la monade) et qui fait qu’un lien brisé n’a jamais empêché le web de fonctionner.
Google : à rebrousse-poils du web
Le projet backrub, qui fut l’ancêtre de Google et du PageRank, prenait le web à rebrousse-poil en se proposant d’identifier les pages HMTL qui lient une page donnée (Cf. L’idée qui fonda Google). C’est prendre le web à rebrousse-poil car les liens HTML sont reconstitués à l’envers : dans un cas la page HTML est le “parent” qui contient les liens vers les pages “enfants”, dans l’autre c’est les pages “enfants” qui lient vers la page “parent” pour lui donner un poids (un ranking).
A ce titre, on peut dire que le modèle d’affaire de Google s’est constitué mathématiquement comme une dualité du web, selon la théorie des catégories : Google = Co(Web).
*
Il serait intéressant de rejouer ce raisonnement en y intégrant ce qu’écarte Meijer, à savoir les bases NoSQL qui ne sont pas sur le modèle document clé-valeur mais sous une forme d’un graphe typé. C’est à dire en prenant en compte les éléments de la présentation (slides) An Overview of Data Management Paradigms: Relational, Document, and Graph, de Marko Rodriguez.
Un billet très intéressant. « On passe son temps à basculer du modèle relationnel au modèle objet puis au modèle document et inversement. » C’est effectivement l’un des gros points noirs du développement Web, en particulier.
NoSQL permet de se passer du modèle relationnel et de supprimer une conversion. Mais il y a aussi l’architecture XRX (XForms, REST, XQuery) qui a fait son petit buzz il y a 2 ans et qui permet de travailler avec le modèle arbre/document d’un bout à l’autre. Christian, as-tu des retours d’expériences sur des projets XRX ?
[Reply]
Qques remarques (au risque de me gourrer…).
Oui, je m’étais fait aussi la remarque que le boulot du développeur web était grandement centré autour
– du transvasement des données d’une couche à une autre, avec transformation des formats
– et de la gestion des conteneurs de données des différentes couches (par ex, httpsession), et des caches pour en obtenir les meilleurs perfs.
Par ailleurs, je ne suis pas convaincu (du tout) que le modèle objet soit défini par intension, et le modèle table défini par extension… à vue de nez, je dirais plutôt le contraire… disons, pour faire court, que je peux voir la définition en intension comme un système de liaison différée (~il faut une main invisible pour recoller les bouts). A ce titre, la donnée d’un pointeur est une définition en extension: pas besoin d’une main invisible, il suffit de suivre le pointeur pour retrouver les données référencées/pointées. Par contre, avec une base de données, avec une foreign key, sans moteur de base de données (la main invisible), d’un point de vue centré sur les tables, si je pars d’une table avec une entrée disposant d’une foreign key, je ne peux pas retrouver l’entrée de l’autre table… sans l’aide du moteur de base de données, donc pour moi, c’est une définition en intension.
Quant à écrire : « On comprend aisément la forte contrainte d’intégrité requise pour les bases de données relationnelles : une modification doit se déployer sur l’ensemble du système, de manière extensive, pour en garantir l’intégrité. Avantage à la maîtrise des données mais difficultés à passer à l’échelle du web. » => il est question ici des bases de données relationnelles, mais cette constatation peut s’appliquer à n’importe quel conteneur de données IMHO ; ou dit autrement, le paragraphe cité indique une généralité, donc si je ne remets pas en cause l’existence du dit paragraphe, j’applique cette généralité à tout type de conteneurs (cf. ma remarque), et si l’on rentre dans les détails (par ex, sharding), alors je pense qu’il faut aussi rentrer dans les détails du sharding pour les bases relationnelles, et du coup, le paragraphe cité n’a plus lieu d’être car trop flou…
A propos du Type System, en quoi faire en sorte que, la fonction ne retourne plus un INT mais à un CHAR, fait que l’on a contourné l’effet de bord ???
Je ne suis pas d’accord avec « POST n’est pas une fonction idempotente (pure) car elle va modifier l’état du système » => un appel POST ou 2 appels POST identiques produise la même modification de données. Donc, je dirais au contraire qu’il y a idempotence (du point de vue fonction).
Je ne suis pas d’accord avec Meijer quant il écrit « Entities have identity » (SQL) et « Environment determines identity (CoSQL) ». Dans les 2 cas, IMHO, « Entities have identity »: pour SQL, les entrées ont une clé (primary key), et pour le CoSQL, pareil, puisque l’on parle ici de clé/valeur ! Si l’on assimile clé & identité pour SQL, je ne vois pas pkoi ce ne serait pas aussi le cas pour le CoSQL.
Quant à ce qui a repoussé les investisseurs approchés par Tim Berners Lee, cela est sans doute moins qu’ils ne comprenaient pas l’intérêt d’un système métastable comme le web, mais plutôt le fait de définir un système ouvert, basé sur des standards, eux-mêmes ouverts.
[Reply]
Christian Reply:
avril 20th, 2011 at 6:06
@ Dominique de Vito :
« je ne suis pas convaincu (du tout) que le modèle objet soit défini par intension, et le modèle table défini par extension… à vue de nez, je dirais plutôt le contraire… »
Je ne te cache pas que j’ai passé 2 heures sur ce point parce que ce n’était pas du tout évident. Dis-toi qu’avec les TABLES, l’identifiant (ici Primary Key) doit être extensivement écrit dans tous les tables. Cela veut dire qu’en voyant une table tu ne peux pas savoir quelles sont les tables qui pointent vers elle (tu ne vois pas la « main invisible » comme c’est le cas avec le modèle Objet-Graphe en utilisant les adresses). Tu vois mieux où pas dit comme çà ?
[Reply]
Christian Reply:
avril 20th, 2011 at 6:13
@ dominique De Vito
A propos du Type System, en quoi faire en sorte que, la fonction ne retourne plus un INT mais à un CHAR, fait que l’on a contourné l’effet de bord ???
Là je me suis trompé, en fait il faut passer à un degré de généralité plus grand. Ce n’est pas passer de INT à CHAR mais de INT à une Collection de INT .
Il faudra que je modifie le texte.
[Reply]
Christian Reply:
avril 20th, 2011 at 6:16
@ Dominique
Je ne suis pas d’accord avec « POST n’est pas une fonction idempotente (pure) car elle va modifier l’état du système » => un appel POST ou 2 appels POST identiques produise la même modification de données. Donc, je dirais au contraire qu’il y a idempotence (du point de vue fonction).
Là, je vais attendre pour répondre à cette question, j’attends d’autres commentaires. Je pense que çà va être intéressant.
[Reply]
Christian Reply:
avril 20th, 2011 at 6:24
@ Dominique
Je ne suis pas d’accord avec « POST n’est pas une fonction idempotente (pure) car elle va modifier l’état du système » => un appel POST ou 2 appels POST identiques produise la même modification de données. Donc, je dirais au contraire qu’il y a idempotence (du point de vue fonction).
Je ne suis pas d’accord avec Meijer quant il écrit « Entities have identity » (SQL) et « Environment determines identity (CoSQL) ». Dans les 2 cas, IMHO, « Entities have identity »: pour SQL, les entrées ont une clé (primary key), et pour le CoSQL, pareil, puisque l’on parle ici de clé/valeur ! Si l’on assimile clé & identité pour SQL, je ne vois pas pkoi ce ne serait pas aussi le cas pour le CoSQL.
C’est un peu le même problème qu’avec la définition par intension et par extension :
Dans un graphe, il y a un des deux noeuds qui ne sait pas que l’autre pointe vers lui (si tu lui pose la question il te répondra qu’il est seul au monde). L’autre, celui qui a un pointeur, connaît l’existence et l’adresse des autres noeuds qui constituent son identité ; de lui-même, il peut retrouver ses petits. Avec SQL les entités *mères* n’ont pas d’adresses vers leurs *fils* ; ici seuls les fils connaissent la mère.
[Reply]
Je reviens à propos du papier de Meijer and co…
Perso, j’ai commencé à lire ce papier, mais je ne l’ai pas encore fini à ce jour.
Bon, Meijer illustre le schéma des données objet et celui des données relationnelles, et indique que les flèches des 2 schémas sont inverses l’une de l’autre. ok.
Ensuite, il introduit les *index* de bases de données. Et c’est peu près que j’ai stoppé la lecture de cet article.
Ceci étant, les flèches des *index* relationels ne sont pas représentées, mais l’eussent-elles été que l’on se serait aperçu que les flèches des index relationnels correspondent aux flèches des données objet.
cf. figure 7 du papier ici http://cacm.acm.org/magazines/2011/4/106584-a-co-relational-model-of-data-for-large-shared-data-banks/fulltext
Perso, je me suis jamais posé de questions précises sur les index de bases de données relationnelles…
Mais si ces index peuvent être bien vus comme des flèches-pointeurs, alors cela me semble ouvrir une perspective car les données relationnelles munies des flèches des index relationnels ressemblent (vu de loin) à l’organisation des données dans une base objet !
Si cette ressemblance est bien effective (à valider), cela veut dire que des données organisées de manière relationnelle peuvent aisément se retrouver (via les index) dans une forme proche de celle des bases de données objet.
Pourrait-on imaginer l’inverse ? Par ex, à partir d’une base de données objet, est-ce qu’avec des index inverses, ne pourrait-on pas rapprocher des données organisées en objet de l’organisation propre à celle d’une base de données relationnelle ?
Et si l’on peut effectivement faire le trajet dans un sens organisation relationnelle=>objet et aussi dans l’autre objet=>relationnelle, quelle valeur donner au discours selon lequel il n’y a que les bases relationnelles et l’organisation relationnelle qui vaillent, et que les bases objet sont une voie de garage ?
C’est troublant cet aperçu détaillé des index relationnels…
[Reply]
Christian Reply:
avril 20th, 2011 at 6:29
@ Dominique :
Mais si ces index peuvent être bien vus comme des flèches-pointeurs, alors cela me semble ouvrir une perspective car les données relationnelles munies des flèches des index relationnels ressemblent (vu de loin) à l’organisation des données dans une base objet !
Exactement. Un index à la forme d’un modèle Objet-Graphe avec stockage clé-valeur. C’est là dessus que se positionne le SEarch Based Application : çà remouline toutes les données de la base relationnelle pour l’exposer en modèle objet-Graphe : tu rajoutes une appli qui requête l’index du moteur de recherche et çà va nettement plus vite.
[Reply]
Le problème du « sens des flèches » est très intéressant. Il se résume à: « Comment figer les relations entre les données sans restreindre ni imposer de cheminements dans ces données ».
Cela a des implications qui dépassent largement le petit monde informatique.
Un article creusant cette question serait peut-être bienvenu?
[Reply]
A propos de l’adéquation naturelle modèle objet/architecture du web:
c’est quelque chose qui saute aux yeux, seule la prépondérance (abusive) du SQL peut expliquer que cette évidence n’ait pas été plus largement reconnue plus tôt.
Pour mémoire, la plateforme ZOPE (voir http://en.wikipedia.org/wiki/Zope ) propose une base de données objet (la ZODB) qui est nativement câblée sur un serveur HTTP fonctionnant comme un broker d’objets, et qui est équipée d’un indexeur d’objets (du genre de Lucene).
Cela en fait un système absolument génial pour le développement web, le détail étonnant étant que cela ait été inventé à la fin des années 1990, que cela continue de s’améliorer depuis, tout en restant assez méconnu.
[Reply]
@Christian
« Ainsi « Idempotence » en REST signifie « Pureté » en langage fonctionnel : la valeur d’une fonction ne change pas dans le temps (pas d’effet de bord). Par où l’on voit que le style d’architecture REST est un style qui s’appuie sur une architecture fonctionnelle pure par défaut : POST n’est pas une fonction idempotente (pure) car elle va modifier l’état du système.. »
@ Dominique
« Je ne suis pas d’accord avec « POST n’est pas une fonction idempotente (pure) car elle va modifier l’état du système » => un appel POST ou 2 appels POST identiques produise la même modification de données. Donc, je dirais au contraire qu’il y a idempotence (du point de vue fonction). »
@Christian
« Là, je vais attendre pour répondre à cette question, j’attends d’autres commentaires. Je pense que çà va être intéressant. »
1ere réaction: doh c’est PUT qui est idempotent pas POST, le b.a.-ba de l’HTTP Restful.
2me lecture: ah oui mais là on fait le parallèle avec la programmation fonctionnelle, et j’ai bien l’impression que l’idempotence n’a pas tout a fait le même sens dans le paragdime REST (qui est un style d’architecture) que dans le paradigme fonctionnel (un style de programmation).
Donc il faudrait définir ce qu’est idempotence du point de vue du paragdime fonctionnel ? Moi ça me dépasse.
Maintenant si on reprend le parallèle PUT/POST. Dans le cas du PUT c’est le client qui décide de tout: contenu de la ressource, URI. Et ce quelque soit l’état des ressources côté serveur, d’où l’idempotence: 2 appels ou + identiques produisent le même effet. Dans le cas d’un POST la modification va dépendre de l’état des ressources coté serveur. Par exemple si j’ai une url qui permet d’effectuer une réservation pour un concert via un POST, deux POST successifs identiques ne vont pas produire le même effet (génération d’un nouveau numéro de réservation, erreur car une même personne n’a pas le droit de faire deux réservations, erreur car il ne reste plus de place lors du 2eme appel,…)
[Reply]
Mince c’est quoi la syntaxe pour faire de jolies citations? Pas de preview avant de poster un commentaire? Mais que fait le maître des lieux!
[Reply]
[…] twitter rss Sens et enjeux des modèles de stockage et d’accès aux données […]
[…] Sens et enjeux des modèles de stockage et d’accès aux données […]
[…] architecture logicielle avec lesquelles il faut composer. Cette note fait écho à celle sur le sens et les enjeux des modèles de stockage et d’accès aux données, et elle me permettra de faire la transition vers la question de l’affordance dans les […]
[…] y a une dualité [mot qui a un sens précis en mathématique dans la théorie des catégories, cf. Sens et enjeux des modèles de stockage et d’accès aux données] entre un système de log et une table de base de données : la table reflète la valeur actuelle […]

Christian Reply:
avril 20th, 2011 at 5:55
@ Pierre D : non je ne vois pas de XRX, en fait cela se fait plutôt à la sauce SBA : http://www.christian-faure.net/2009/08/01/search-based-applications/
[Reply]