Défaut: Architecture CoSQL Métadataware métastabilité Meijer programmation
by Christian
19 comments
Sens et enjeux des modèles de stockage et d’accès aux données
C’est typiquement le genre d’article qui nécessite des corrections, des remarques et peut-être un débat. Alors n’hésitez pas.

Code et data
Pas de code sans données, car le but d’un code est de tourner et de produire des résultats et, pour ce faire, le code doit “manger” des données.
On peut voir le code dans sa forme la plus abstraite comme un algorithme dont le rôle serait de produire des preuves. Mais on peut aussi voir le code comme un algorithme qui ne fait pas simplement que valider et prouver mais également qui produit des changements d’états et des évènements qui, au sens littéral du terme, changent le monde.
On a ici un parallèle avec les “speech acts” de Searle et Austin dont Henry Story avait parlé dans son intervention au MeetUp Semantic Web de Février 2011.
Quiconque écrit un programme s’attend en effet à “changer le monde”, ne serait-ce que pour écrire “Hello World” sur un terminal. Changer le monde avec des algorithmes et du code, Microsoft, Google, Facebook et d’autres l’on fait, et l’ensemble des développements en Open Source peut-être plus encore.
Pas de code sans données donc. Or ces données sont stockées dans des supports de mémoires différents selon qu’elles sont en mémoire vive, sur un système de fichier, ou dans une base de donnée. Et chaque support de mémoire utilise un modèle de données qui n’est pas forcément le même. Ce qui nous ramène à la difficile collaboration entre les développeurs et les gestionnaires de base de données.
Si les développeurs et les administrateurs de base de données doivent collaborer, la réalité est parfois toute autre : les développeurs ne comprennent pas toujours le SQL et les RDB (bases de données relationnelles), et les DBA (administrateurs de base de données) ne voient les développeurs que comme de dangereux cowboys qui veulent massacrer l’intégrité de leur données (“mon précieux …”).

Le DBA

Le développeur
Transfert ou transport ?
L’emploi de ces deux synonymes que sont « transfert » et « transport » a attiré mon attention après avoir constaté que, même si parfois les deux termes sont utilisés de manière quasi interchangeable (« transfert ou transport »), il y avait aussi des cas d’usages dans lesquels prédominait l’utilisation d’un des termes plutôt que de l’autre.
Qu’en est-il donc ? more »
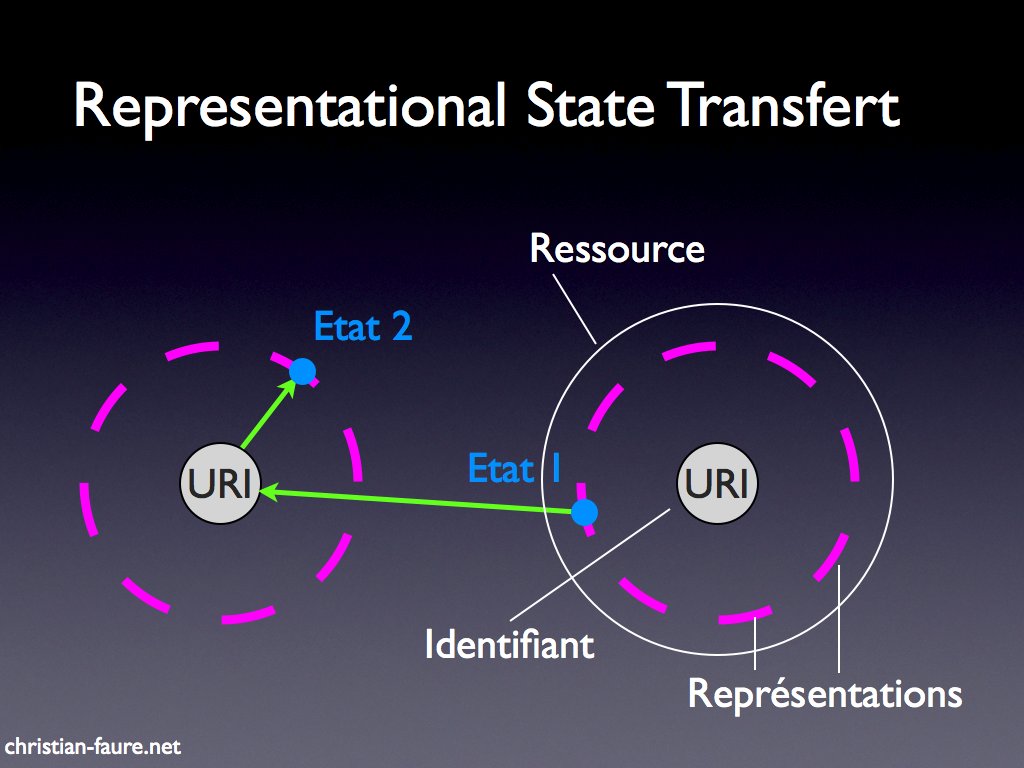
REST en image
On a beau dire, parler de « Representational State Transfert » reste souvent un terme auquel il est difficile d’associer une représentation imagée.
Pourquoi parle-t-on d’état ? De représentation ? Et de transfert ?
Cette image peut aider :
Atomiser son Système d’Information
S’il y a un des mérites qu’il faut reconnaitre à la mode des architecture RESTful c’est bien celui d’avoir rappelé cette évidence : HTTP est un protocole applicatif, et donc que le web est une application.
Et à qui me demande aujourd’hui « qu’est ce que REST ? », je réponds simplement que c’est d’abord un principe d’architecture dans lequel les données et les informations ont des adresses (URI), ce qui est déjà énorme quand on doit traiter des problématiques d’accès à l’information et d’interopérabilité entre des systèmes d »informations. On peut donc faire beaucoup de choses dans un système d’information en considérant HTTP comme un véritable protocole applicatif, et pas seulement comme un protocole de transport.
Dans une architecture RESTful, la plupart des échanges via les APIs se font en utilisant des messages XML. On peut donc construire des Architectures RESTful pourvu que des APIs soient RESTful, c’est à dire qu’elles respectent un certain nombre de principes. On peut même enrichir la démarche en s’appuyant à la fois sur un vocabulaires XML, c’est que l’on fait en utilisant le vocabulaire XML ATOM, et en utilisant un protocole applicatif qui s’appuie sur – et respecte – HTTP, c’est ce que fait le protocole de publication Atom (ATOMPUB). Ainsi, au dessus de HTTP/XML on peut utilsier ATOMPUB/ATOM, tout en respectant les principes REST.
more »
Défaut: Architecture Intelligence milieu_associé milieu_dissocié REST SOA
by Christian
6 comments
Une certaine conception de la souveraineté s’exprime aussi dans les choix d’architecture
Dans son Post-scriptum sur les sociétés de contrôle (1990), Deleuze commence par rappeler le travail fait par Foucault qui a décrit l’avènement des sociétés de disciplinaires des 18° et 19° siècles, qui atteignent leur apogée au 20° siècle :
Elles [les sociétés disciplinaires] procèdent à l’organisation des grands milieux d’enfermement. L’individu ne cesse de passer d’un milieu clos à un autre, chacun ayant ses lois : d’abord la famille, puis l’école (« tu n’es plus dans ta famille »), puis la caserne (« tu n’es plus à l’école »), puis l’usine, de temps en temps l’hôpital, éventuellement la prison qui est le milieu d’enfermement par excellence.
De l’intérêt d’un Portail d’Entreprise
 Dans tout projet d’intégration d’entreprise visant à agréger des services provenant de différents silos applicatifs, le serveur d’application centralisé semble être une évidence, et l’on parle alors de Portail d’Entreprise.
Dans tout projet d’intégration d’entreprise visant à agréger des services provenant de différents silos applicatifs, le serveur d’application centralisé semble être une évidence, et l’on parle alors de Portail d’Entreprise.
On écoutera patiemment les arguments des éditeurs de telles solutions ainsi que ceux des DSI qui vantent les qualités du portail d’entreprise comme point d’entrée centralisé (maîtrisé, personnalisable, sécurisé, etc.) pour l’ensemble d’un porte-feuille applicatif.
Qu’est-ce qu’une « URI déréférençable » ?
 Manue vient de publier quelques bons billets suite à sa participation à la 7ième conférence internationale sur le web sémantique (ISWC 2008).
Manue vient de publier quelques bons billets suite à sa participation à la 7ième conférence internationale sur le web sémantique (ISWC 2008).
Dans un de ces billets, intitulé ISWC 2008 (3) – être visible sur le Web : linked data, elle rappelle une règle de base pour publier ses données en RDF sur Linked Data :
Une consigne de base : mettre le plus possible de liens (je veux dire, d’URIs déréférençables) dans les triples, pour faciliter la navigation dans le Web of data.
Je pense que l’expression « URI déréférençables » est loin d’être évidente pour tout le monde. Qui plus est, derrière ses faux airs, le verbe déréférencer fait immanquablement penser à autre chose : notamment à l’action de supprimer une référence, ou de ne plus référencer, ce qu’il ne signifie pas du tout dans ce contexte.
Alors, avant que nos bibliothécaires ne se méprennent et commencent à enlever les références de leur catalogue pour faire du web sémantique, une petite clarification s’impose.
Le style d’architecture SOA
Invité comme conférencier à la réunion annuelle des directions informatiques du Ministère de l’Éducation Nationale qui se tenait à Cannes, j’ai pu mesurer – une fois de plus – le fossé qui se creuse entre d’une part la manière dont on parle des systèmes d’information, dont on vend des projets informatiques, et d’autre part la manière dont on réalise les projets informatiques.
La vérité sur la SOA
Roy Fielding, a propos des SOA, des « Service Oriented Architecture » sur la liste de discussion REST :
The reasonable conclusion is that SOA is neither an architecture nor a style, but rather a set of goals that can be sold to overmatched CIOs regardless of the corresponding architecture or implementation.
Faut-il se réjouir de l’indexation de Flash ?
La nouvelle a vite fait le tour de la blogosphère : Adobe, Yahoo et Google ont signé un partenariat pour indexer les fichiers flash.
Les premières réactions que j’ai pu lire sont plutôt positives. Mais je reste dubitatif devant cette initiative, et ce pour certaines raisons :
