Introduction au Text-mining
Les outils de text-mining ont pour vocation d’automatiser la structuration des documents peu ou faiblement structurés.
Ainsi, à partir d’un document texte, un outil de text-mining va générer de l’information sur le contenu du document. Cette information n’était pas présente, ou explicite, dans le document sous sa forme initiale, elle va être rajoutée, et donc enrichir le document.
A quoi cela peut bien servir ?
- à classifier automatiquement des documents
- à avoir un aperçu du contenu d’un document sans le lire
- à alimenter automatiquement des bases de données
- à faire de la veille sur des corpus documentaires importants
- à enrichir l’index d’un moteur de recherche pour améliorer la consultation des documents
Bref, plusieurs usages et plusieurs services peuvent découler des solutions de text-mining.
Comment çà marche ?
Il y a quelques règles de base que les outils de text-mining se doivent de respecter dans leur traitement. Ces règles de base sont plus ou moins chronologiquement les suivantes :
- D’abord le logiciel doit reconnaître les unités de la langue que sont les mots (tokenisation)
- Ensuite il doit savoir interpréter et prendre en compte la ponctuation et la mise page (retour à la ligne, paragraphe, etc.)
- Puis les formes lexicales et grammaticales, qui peuvent énormément varier selon que la langue est l’anglais, l’arabe ou le chinois.
- Ensuite, il y a une phase de lemmatisation : elle consiste à identifier les différentes flexions d’un terme, ou déclinaisons d’un verbe.
L’ensemble des phases précédentes relèvent de ce que j’appelle l’analyse linguistique, au sortir de laquelle nous avons un document que le logiciel de text-mining a transformé. Si le document initial était fait pour les yeux de l’humain, le document après traitement est fait pour un traitemtn par les machines.
Deux approches, qui ne sont pas antinomiques, peuvent ensuite être envisagées :
- une approche statistique
- une approche sémantique
1. L’approche statistique :
Elle consiste à ne voir le document que via le prisme du nombre et des chiffres.
Ainsi l’outil statistique de text-mining produit des informations sur le nombre d’occurrence d’un terme, le nombre de cooccurrence de plusieurs terme, la fréquence d’apparition d’un terme dans un document ou un corpus.
Il peut encore produire ce que l’on appelle des « vecteurs de sens », qui sont des « concepts » statistiques de cooccurrence de termes qui permettent de classer et/ou de catégoriser tout un corpus.
- Les avantages de l’approche statistique :
Le principal réside dans son très faible coût d’entretien eut égard au véritable service que cela peut apporter, à condition que le volume du corpus documentaire soit significatif, voire très important.
- Les désavantages de l’approche statistique :
Le revers de la médaille, c’est qu’il n’y a pas de prise en compte des spécificités du corpus documentaire traité : textes médicaux, commerciaux, scientifiques ou autres, seront adressés de manière identique, grâce à la puissance du calcul statistique.
Autre élément à prendre en compte, c’est la pertinence du traitement qui est non seulement difficilement prévisible, et en tout cas généralement moins élevée que l’approche sémantique.
2. L’approche sémantique :
Dans le cas de l’approche sémantique, la démarche ne va plus s’appuyer sur la force brute de la puissance de calcul mais sur un élément externe. Cet élément externe, appelons le référentiel. Il peut être statique ou dynamique.
Une fonction comme la reconnaissance d’entité (entity recognition) va ainsi déduire que le groupe de mots « Christian Fauré », écrit sans plus d’information dans un document, est une personne de nationalité française parce que le moteur de text-mining aura été cherché mon nom dans un référentiel de personne, et qu’il l’aura trouvé dans la catégorie « personne de nationalité française ».
Les référentiels statiques peuvent être des mots clés, des listes à plats, des thesaurus, des ontologies. Le moteur de text-mining va rajouter aux documents qu’il traite l’ensemble des informations que peut contenir le référentiel.
Les référentiels dynamiques existent aujourd’hui surtout dans ma tête. Ce sont des référentiels qui mettent en oeuvre des logiques. Celles-ci peuvent être des logiques formelles (celles que décrivent OWL), mais aussi des logiques probabilistes (comme les réseaux bayesiens). La différence avec le référentiel statique est que le document qui passe par le moteur de text-mining va être enrichi par des informations qui sont déduites du référentiel : le référentiel fait un travail de déduction avant de donner sa réponse au moteur de text-ming qui va enrichir le document.
- Les avantages de l’approche sémantique :
On peut paramétrer le moteur de text-mining pour coller à la spécificité du corpus documentaire en exploitant l’ensemble des référentiels du domaine ou de l’organisation. On peut également modéliser des connaissances métiers spécifiques pour effectuer des traitements de text-mining qui répondent à un besoin bien identifié. La pertinence des résultats obtenus est beaucoup plus fine et généralement meilleure que dans l’approche statistique (la notion de « meilleur » étant toute fois toujours relative).
- Les désavantages :
Le coût d’exploitation et de maintenance est très fort. Cela demande des ressources matérielles, budgétaires et humaines significatives. De plus si le corpus est important, le temps de traitement requis peut être très long et représenter un frein à la démarche.
3. Quelle complémentarité des approches statistiques et sémantiques ?
Comme je l’ai déjà dit, ces deux approches du text-mining (statistique et sémantique) ne sont pas antinomiques. Pour éclairer la complémentarité des approches je vais prendre l’exemple des moteurs de recherche.
Je considère en effet, mais c’est une conviction personnelle, que la meilleure valorisation des outils de text-ming c’est de les utiliser afin d’enrichir l’index d’un moteur de recherche.
Je prendrai deux exemples concrets : le premier avec le moteur de recherche de FAST et le deuxième avec la plate-forme UIMA corrélée au moteur de recherche OmniFind d’IBM.
Ces deux solutions ont en commun de proposer un « tuyau de traitement » des documents avant indexation.
Chez FAST, cela donne quelque chose qui peut s’illustrer de la manière suivante : un tuyau dont les anneaux sont autant d’étapes de traitement et d’enrichissement du document initial. Chaque étape enrichie le document tel qu’il arrive dans le tuyaux et le renvoie dans le tuyau pour une nouvelle étape de traitement.

Les premiers anneaux de traitement sont ceux de la normalisation et de l’analyse linguistique évoquées plus haut, ensuite les traitements peuvent être de type statistique ou sémantique. A la fin des traitements, le document est indexé et accessible vie le moteur de recherche. Entre temps, il est devenu structuré.
Le fait est que ce tuyau est la propriété de FAST, et les outils de text-mining tiers ne peuvent pas s’y greffer facilement.
C’est là qu’arrive IBM.
Le moteur OmniFind d’IBM n’a pas la réputation d’être un foudre de guerre, et il est en tout cas commercialement peu présent sur un marché dominé par les grands acteur du Search en entreprise et les petits éditeurs dynamiques. Aussi, pour tenter de s’imposer, IBM a proposé en open source son Bus Middleware, qui correspond au tuyau de traitement et d’enrichissement avant l’indexation par le moteur de recherche. Ce bus middleware s’appelle UIMA (Unstructured Information Management Architecture) et son architecture peut être illustrée de la manière suivante :
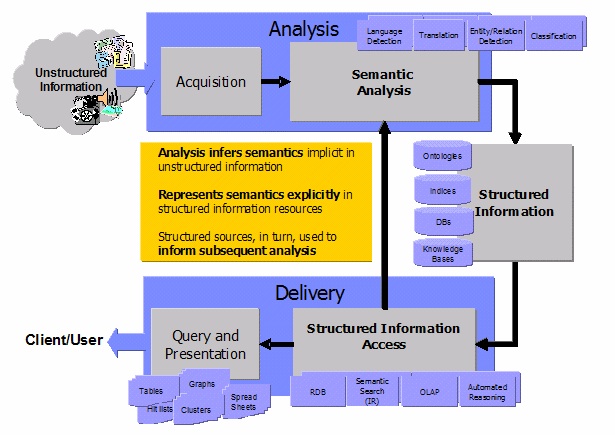
Comme UIMA est ouvert et libre, IBM souhaite s’imposer, non pas comme outil de text-mining, mais comme l’architecture qui permet d’accueillir divers outils de text-mining tiers. Ainsi la solution de l’editeur de text-mining TEMIS est « UIMA compliant » : on peut les « plugger » sur le bus UIMA d’IBM.
On peut quand même se demander si, au bout de la chaîne UIMA, le moteur de recherche qui va exploiter toute cette chaîne de traitement peut être autre chose que le moteur OmniFind d’IBM ; « j’en doute » me disait récemment un consultant. Mais c’est quand même bien joué de la part d’IBM, acteur reconnu du Middleware, de se positionner comme le Middleware ouvert du monde du traitement des informations non-structurées.
Si cette note pouvait permettre aux entreprises d’arrêter d’imaginer que le text-mining est une solution magique, elle aurait atteint son but. C’est une solution technique qui a des impacts budgétaires, organisationnels et métiers qu’il faut clairement identifier.
Je rappelle également qu’il existe une autre méthode pour structurer les documents : c’est de les structurer dès leur création en menant une politique éditoriale (je passe la main à Got).
Le tout est de savoir où on veut mettre le curseur… et son argent.
UIMA est assez nul en réalité. Sur le papier ça semble alléchant, mais dans la vraie vie c’est une énorme machine à gaz. D’ailleurs, comme vous le faites remarquer, TEMIS se dit « UIMA Compliant », mais combien ont réellement mis en place le framework complet ? A ma connaissance, aucun. Enfin si… Thales…
… Thales, qui est passé à UIMA parce qu’un de ses chefs vient d’IBM, évidemment. D’ailleurs, j’ai ouï dire que pour adapter UIMA à leurs besoin, ça a déployé une énergie considérable.
Compte tenu du fait que la documentation (bien que très conséquente) est floue, et que l’activité sur les divers forum, proche de zéro, on peut quand même s’interroger sur la pertinence de cet outil pour autre chose que des projets monstrueusement gros (on note qu’IBM a refilé le bébé à la fondation Apache il y a peu… parce que c’est un échec ? mystère).
[Reply]
[…] A rapprocher de ce que fait l’UIMA d’IBM ou le Document Processing de FAST, dont je parlais dans mon introduction au text-mining. XML (No Ratings Yet) Loading … […]
Oui UIMA est compliqué.
Non il ne remplace ni les outils de text-mining, ni les outils sémantiques.
Il y a un vrai fossé entre les outils d’extraction automatiques d’information et les outils sémantiques; ce fossé se réduira petit à petit au fur et à mesure des avancées des différentes technos, mais elles ne pourront jamais converger avant (très très) longtemps. UIMA est là pour lancer un pont par dessus ce fossé, et, si on considère la question sous l’angle du web sémantique et non plus sous un angle business, il y a un vrai besoin de combiner les deux mondes.
UIMA est très proche de ce que nous avons déjà fait chez Mondeca, et de ce point de vue, nous comprenons tout à fait et ses objectifs, et son architecture. Bref nous ne sommes pas tellement dépaysés. UIMA est compliqué justement parce que (pour m’y être déjà essayé) relier ces deux mondes est compliqué.
[Reply]
Pour connaître un peu Temis, leur solution utilise bien le framework UIMA de bout en bout. Et la plupart de leurs clients conserve cette ossature.
Maintenant il est vrai qu’UIMA est encore jeune et parfois limité, mais avec le temps il aura sans doute la chance de s’améliorer en fonction des feedbacks de chacuns. A eux de prouver qu’ils sont a l’écoute pour faire réellement évoluer le projet vers un standard.
Time will tell…
[Reply]
Pour « rebondir » sur le post de Thomas FRANCART, il existe un réel fossé entre les outils : A mon sens, c’est surtout lié aux contraites linguistique…mais aussi parce que ce marché et en phase de structuration.
Chez Verticrawl (puisque vous parlez des « petits editeurs dynamiques [français] »…), à l’inverse de FAST, nous privilégions une architecture modulaire et non pas en tube. Certaines opérations peuvent s’effectuer avant indexation et d’autre post, pour enrichissement ou traitements diverses. Nous pouvons donc traiter tous les « greffons » que nous souhaitons…
Cela nous permet l’intégration de contenus structurés et non-structurés pour enrichir les recherches.
Par exemple, les processus de text mining sont fait durant l’indexation et les opérations de taggage diverse (email, adresse, téléphone) sont produites à posteriori.
Coté WEB SEMANTIQUE :
On parle beaucoup du web 3.0 comme « LE sémantique », il semble interessant de reconsidérer le moteur de recherche comme un moteur de réponse.
Certains projets comme « CUIL » nous semble plutot interessant (bien que peut-être un peu presomptueux ?) mais pose là un vrai pont entre le text-mining et la sémantique appliquée .
A quand un moteur qui nous donne enfin l’age du capitaine ?
[Reply]
slt tout le monde
je cherche de la documentation sur le Text mining j’ai travail a faire sur ce sujet mais je pas de doc concrète alors si qlq un peut m’aide
merci
[Reply]
[…] de projet. Taskjuggler : Logiciel de gestion de projets open source. Les outils de Text Mining. Introduction au Text-mining. “Feed to Javascript"? : Transformer un flux rss en javascript. Zetoc: Homepage : Service […]
[…] on November 7, 2009Filed Under liens | | Christian Fauré » Blog Archive » Introduction au Text-miningtags: textmining, moteur de rechercheA quoi cela peut bien servir ? à classifier automatiquement […]
[…] this link: Introduction au Text-mining – Christian Fauré Share this […]
bonjour, j’aimerais savoir s’il existe un logiciel de fouille de donnée en francais, qui peut chercher dans des textes francais, et faire des relations, nous permettre de faire nous meme la matrice des codes, qui permet aussi l’indexation des données dans des textes etc… en francais et si possible en open source puisque c’est un projet personnel et non commercial
[Reply]
bonjour à tous
dans le cadre de mon mémoire de master 2, je doit monter un logiciel pour l’évaluation du pourcentage de la courverture du programme scolaire par les professeurs à partir des cahier de texte.
est-ce du text mining?si oui comment proceder?
merci d’avance
[Reply]
by Text mining : quand le texte devient donnée | Introduction aux humanités numériques
[…] L’article de Christian Fauré : Introduction au Text-mining […]

Le monde me semble petit à la découverte de ce blog : ancien élève de B. Stiegler à l’UTC, j’ai raté de peu la séance sur l’éducation à Ars Industrialis… et surtout, je travaille chez un éditeur de logiciel d’analyse sémantique (Arisem).
A ce propos, j’ai quelques commentaires :
– le défaut des algorithmes statistiques, c’est à mon avis surtout l’inertie lorsqu’un événement change la signification des mots employés. Un document du 20 mai mentionnant le « président de la république » pourrait facilement être classé avec ceux parlant de J. Chirac si le corpus passé est important.
Cette inertie se fait particulièrement sentir sur les informations en contexte évolutif, comme par exemple la veille concurrentielle…
– le temps de traitement de l’analyse sémantique est lié aux technologies employées et pas au paradigme de l’analyse sémantique. Il serait imprudent d’exclure l’apparition prochaine d’une technologie d’analyse sémantique très rapide.
– le coût d’exploitation de la sémantique est essentiellement celui de la production et du maintien des référentiels linguistiques et ontologiques. Dans le domaine médical, les ontologies et lexiques existent déjà. Le coût de mise en oeuvre de l’analyse sémantique revient alors à sa juste estimation.
C’est à mon sens la gestion de la connaissance au sens large qui est coûteuse pour une organisation, c’est-à-dire le passage d’un mode productif à un mode réflexif… le niveau d’organisation est un présupposé de l’emploi de la technique, pas sa conséquence. C’est pour avoir ignoré cette distinction que les projets d’ERP des années 80-90 ont traumatisé des sociétés entières.
A très bientôt pour un commentaire sur le commentaire !
[Reply]