Éléments pour la conception des APIs Hypermédias
L’article sur Web APIs 101 se terminait en disant que les démarches de conception d’APIs pouvait alors seulement commencer. J’ai pensé qu’une précision sur les éléments de conception des APIs Hypermedia serait utile.

Ressources, Représentations & Etats applicatifs
HTTP est un protocole de transfert applicatif qui se différencie des autres protocoles de transfert en ce qu’il distingue les Ressources des Représentations. Cette couche d’abstraction supérieure (la ressource) justifie pleinement l’expression de Tim Berners Lee selon laquelle les questions d’architecture du Web peuvent être qualifiées de “philosophical Engineering”. C’est également cette différence entre Ressources et Représentations qui fonde le discours de Roy Fielding sur le style d’architecture REST et qui transparaît dans les spécifications HTTP.
En essayant de donner une représentation imagée de REST, je ne faisais que représenter des changements d’états initiés par des clients sur fond de cette interface uniforme qui s’architecture autour des ressources, des identifiants (URI) et des représentations :

Pour la suite de mon propos, il faut préciser auparavant ce que j’appelle ici des “changements d’états”. De quels états parlons-nous ? » :
- état d’une application (d’une session) du côté du client ;
- ou état d’une ressource du côté du serveur.
Dans REST on parle plus souvent de « sans état » au sens où le serveur n’attend rien de particulier d’une requête du client. Cette absence de gestion d’état du client sur le serveur fait que le cheminement de l’état du client (état 1 vers état 2 dans mon schéma) se décide depuis et par le client mais grâce aux descriptions et aux hyperliens renvoyés dans le message du serveur.
C’est une navigation “à la carte” : le client choisit en fonction de ce que lui présente le serveur. Le serveur sert des réponses qui sont comme un menu, si possible contextuel, au sein duquel le client va faire ses choix d’activation qui vont déclencher son propre changement d’état.
Finalement, c’est comme au restaurant quand on passe sa commande en consultant le menu.

L’importance du message
Cela donne un relief particulier au mécanisme d’échange de messages entre le client et le serveur qui ne peut pas être réduit à un simple transport de données brutes sans avoir des conséquences importantes sur l’architecture logicielle (cf. Architectures logicielles et APIs hypermédias):
Le standard des messages HTTP est constitué de d’une ligne de requête/ réponse, d’une entête (Header) et d’un corps de message (Body) et permet donc d’avoir une couche de métadonnées dans le Header du message :

Un autre type de métadonnées également possible : il s’agit de la possibilité d’avoir des métadonnées, sous forme de liens, au sein même du MediaType transferré. C’est à dire d’avoir des fonctions de type hypermedia intégrées au sein même du corps des messages transférés par le serveur, et qui peuvent être utilisées par le client pour contrôler le flux applicatif (changement d’état applicatif du client).
[mediatype, format de données et types de représentations sont ici considérés comme synonymes ]
Jusque là je n’ai fait que rappeler quelques évidences sur HTTP. Ces considérations mènent tout droit à des architectures RESTful, au moins au sens où elles tentent de respecter et de coller au protocole HTTP, et qui consistent à concevoir des applications à partir d’URI design sur la base desquellles des opérations CRUD seront effectués. Mais bien souvent, ces architectures REST que l’on qualifie de “Pragmatic REST” n’implémentent pas un aspect que soulignait Fielding dans sa thèse : “Hypermedia As The Engine Of Application State” (HATEOAS).
L’interface, c’est le message

Pour comprendre la démarche, il faut partir du constat qu’il est toujours difficile de maintenir des applications distribuées, et plus encore quand ces applications reposent sur des APIs web :
- une mise à jour côté serveur d’une API web peut mettre dans les choux des clients qui nécessiteront une mise à jour du code côté client ;
- un changement de nom de DNS et c’est toutes les URIs qui devront être modifiées aussi bien côté serveur que client ;
- de nouveaux états applicatifs côté serveur qui ne sont pas compris ou mal compris par les clients ;
- etc.
La plupart des soucis de maintient du couplage entre client et serveur doivent être analysée à l’aune de ce qui est un deuxième constat : la plupart des échanges de messages entre le serveur (l’API web) et le client sont des envois de “données brutes”. Il s’agit des objets que gère l’application (Ordre, Client, Liste du Catalogue,…) qui sont sérialisés (souvent en XML, JSON) pour être envoyés au client.
Cet envoi de données brutes sérialisées n’est compréhensible pour un client qu’à condition d’avoir :
- soit un schéma partagé des données dans un document auquel chacun, client et serveur, devront se conformer (approche WS-*/SOAP).
○ Désavantage : chaque changement du schéma partagé doit faire l’objet d’une mise à jour du code côté client et serveur
- soit d’avoir des mécanismes de constructions d’URI qui vont contenir des informations sur les représentations sérialisées dans les messages (approches REStful de la plupart des frameworks MVC)
○ Désavantage : c’est le framework qui décide du design des URIs et on perd la main en restant dépendant d’un code source propriétaire.
- soit ajouter des infos au contenu brut transféré (ajouter des balises au XML ou au JSON)
○ Désavantage : ici aussi ces informations ajoutées sont tributaires du source code côté serveur qui, s’il change, peut avoir des impacts sur le fonctionnement des clients.
- soit, enfin, créer un mediatype public pour chaque objet d’une application faisant l’objet d’un transfert.
○ Désavantage : la multiplication des mediatype deviendrait rapidement ingérable.
Selon Mike Amundsen, il faut à présent voir le problème autrement :
La question que les architectes et designer doivent se poser n’est pas “Comment un serveur doit-il exporter ses objets privés de sorte que les clients puissent les comprennent et les utiliser ? “, mais plutôt “Comment un client et un serveur peuvent partager une compréhension commune des données brutes échangées entre eux ?” Building Hypermedia API with HTML5 and Node.

Il faut donc arrêter de raisonner en terme de synchronisation entre clients et serveurs, la description des données échangées ne doit pour cela en aucun cas être soumise à un langage de programmation, un framework ou n’importe quel autre logiciel y compris l’OS.
Il faut – et c’est moi qui précise ici – se demander qu’est-ce qui joue le rôle d’interface ? A la vérité, dans les exemples que nous avons vu précédemment, l’interface était soit le document de schéma partagé des données, soit la nature des URI, soit des ajouts de balises, soit de nouveaux mediatype publics. La force de l’approche hypermedia est qu’elle consiste à poser que c’est le message qui fait l’interface.
L’approche Hypermedia
L’approche hypermedia consiste à rajouter deux types de métadonnées aux sein même des données brutes contenues dans le message échangé entre serveurs et clients :
- Des métadonnées sur les données (fonction descriptive)
- Des métadonnées sur les options possibles de changement d’états de l’application (fonction hypermedia)
Avec cette approche, on privilégie la stabilité et la flexibilité des architectures logicielles distribuées. Les clients des APIs web ainsi conçues peuvent piloter les changements d’états de l’application : c’est ça l’hypermedia.
Avec cette approche, c’est le message qui transfère des états applicatifs et non des objets applicatifs. Rappelons que par état applicatif on entend la configuration unique des données de l’application à un instant donné et “vue” par le client. Ces états qui sont requettés par le client sont formalisés dans des représentations. Aussi, quant on fait la conception d’une API, on doit commencer par se poser une question simple : quels sont les représentations qui seront requettées par le client, et comment seront-elles transferées ?
C’est pour répondre concrètement à cette question que les H-Factors ont été formalisés. Le message est ici important pour la communauté Web Sémantique car il stipule explicitement qu’il ne faut par se lancer dans une logique d’API pour RDF mais plutôt dans la conception de sérialisations RDF qui supportent des fonctions hypermédias que sont les H-Factors (API for RDF ? Don’t do it !)
H – Factors
Jusqu’à présent j’ai surtout parlé de HTTP et des messages HTTP. Maintenant nous descendons d’un cran au niveau du format des données qui constituent le corps d’un message HTTP ou MediaType (HTML, XML, JSON, PNG, SVG, etc.).
Mike Amundsen a identifié 9 facteurs qu’il appelle les “Hypermedia Factors” et qui constituent l’ensemble des possibilités hypermedia que peut contenir un MediaType.
Dans le schéma ci-après, il y a cinq facteurs qui sont relatifs à la nature des liens hypermedia supportés par le mediatype (chacun représentant la possibilité pour un client de requêter/modifier l’état d’une application), et quatre qui sont relatifs aux métadonnées applicables lors du déréférencement de ces liens (si le protocole HTTP est utilisé, cela revient à avoir les options du HEADER HTTP dans le MediaType lui-même).
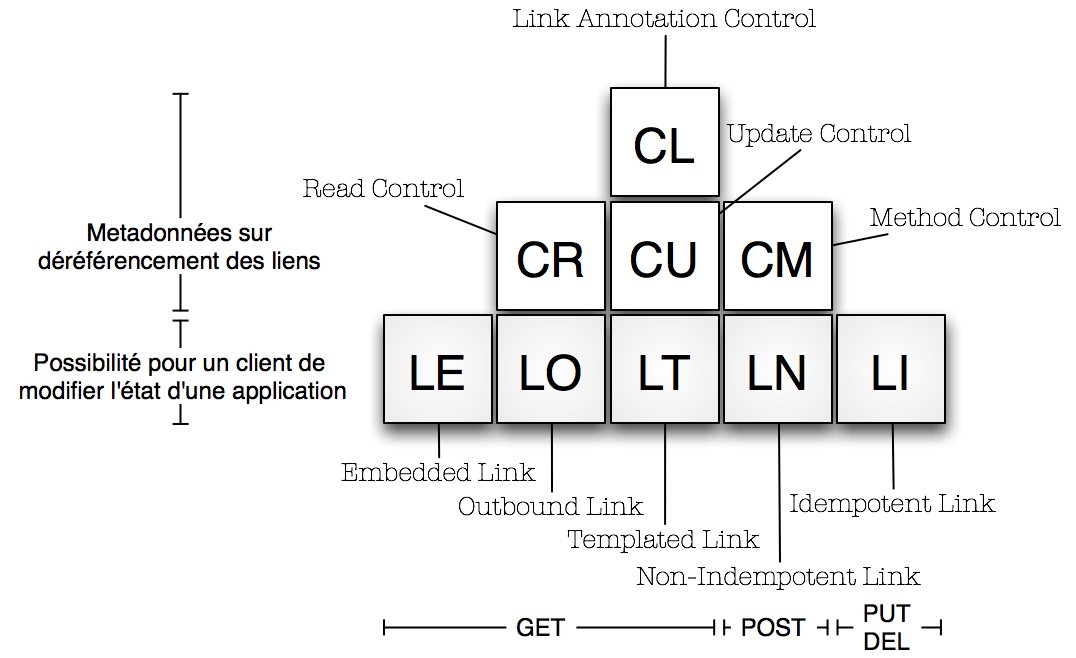
Je reproduis ci-après et sans la traduire la description sommaire mais très claire qu’en propose Amundsen avec les exemples :
Les liens
LE
Support for embedded links (HTTP GET)
<img src="http://www.example.org/images/logo" title="company logo" />
LO
Support for out-bound navigational links (HTTP GET)
<a href="http://www.example.org/search" title="view search page">Search</a>
LT
Support for templated queries (HTTP GET)
<form method="get"> <label>Search term:</label> <input name="query" type="text" value="" /> <input type="submit" /> </form>
LN
Support for non-idempotent updates (HTTP POST)
<form method="post" action="http://www.example.org/my-keywords"/> <label>Keywords:</label> <input name="keywords" type="text" value="" /> <input type="submit" /> </form>
LI
Support for idempotent updates (HTTP PUT, DELETE)
function delete(id)
{
var client = new XMLHttpRequest();
client.open("DELETE", "/records/"+id);
}
Les Contrôles
CR
Support for modifying control data for read requests (e.g. HTTP Accept-* headers).
<xsl:include href="http://www.exmaple.org/newsfeed" accept="application/rss" />
CU
Support for modifying control data for update requests (e. g. Content-* headers).
<form method="post" action="http://www.example.org/my-keywords" enctype="application/x-www-form-urlencoded" /> <label>Keywords:</label> <input name="keywords" type="text" value="" /> <input type="submit" /> </form>
CM
Support for indiciating the interface method for requests (e.g. HTTP GET,POST,PUT,DELETE methods).
<form method="post" action="http://www.example.org/my-keywords" /> <label>Keywords:</label> <input name="keywords" type="text" value="" /> <input type="submit" /> </form>
CL
Support for adding semantic meaning to link elements using link relations (e.g. HTML rel attribute).
<entry xmlns="http://www.w3.org/2005/Atom"> <title>Atom-Powered Robots Run Amok</title> <id>urn:uuid:1225c695-cfb8-4ebb-aaaa-80da344efa6a</id> <updated>2003-12-13T18:30:02Z</updated> <author><name>John Doe</name></author> <content>Some text.</content> <link rel="edit" href="http://example.org/edit/first-post.atom"/> </entry>
Quelques exemples de Profils H-Factors (SVG, Atom, HTML) :



XML vs JSON
L’écrasante majorité des formats de données (MediaTypes) utilisés par les APIs pour transférer des états applicatifs sur le web sont soit du XML soit du JSON (sérialisation des objets applicatifs).

Ce qui fait d’ailleurs que la question du format de donné utilisé par l’API fait l’objet de polémiques par ailleurs bien inutiles (mais bon, çà peut faire du bien de troller et çà peut aussi faire rire).

Or, si l’on applique ces deux formats aux facteurs hypermedias précédemment présentés, on se rend compte que ni XML, ni JSON ne sont nativement des formats hypermedia : XML et JSON n’ont aucune prise en charge des liens dans leur format natif !
Sachant que la tendance est nettement de faire des APIs REST, on peut se demander pourquoi les architectures RESTful, sensées faire de l’hypermedia le moteur de leurs états applicatifs, plébicitent-elles des formats de données qui n’ont en natif aucune capacité à embarquer des liens dans leur message (aucun H-Factor) ?
On voit donc à quel point HATEOAS n’est pas du tout marginal dans le style d’architecture REST. En la matière, la dimension hypermedia est la plus dure à mettre ne oeuvre dans les APIs ; la raison en est que les concepteurs d’APIs raisonnent majoritairement en fonction de du langage de programmation et cèdent à la tentation de concevoir l’interface non pas dans le message lui-même mais dans la sérialisation des objets applicatifs, de fait très intimement imbriquée et dépendante du code.
La différence entre objet applicatif et état applicatif n’est pas encore assez claire dans les esprits.
Pour palier à l’absence de facteurs hypermédia dans XML ou JSON, ceux qui vont implémenter la solution technique vont devoir implémenter d’autres formats, par exemple avec XLinks et XForm pour XML alors qu’aucun standard n’existe pour JSON (JSON-LD n’est pas à ce jour un standard) où il faudra concevoir “from scratch” les H-Factors que l’on veut implémenter.
“Code on demand”
Ce qui m’amène au deuxième point pour palier à l’absence de H-Factor natifs dans XML et JSON : ll’utilisation du “code on demand”. Par exemple, en faisant un GET sur la représentation HTML d’une ressource, un client récupère le HTML plus le code Javascript qui va rendre le client riche et plus “intelligent”, notamment pour comrpendre le JSON échangé. Ici, JSON doit bien évidemment son succès à la présence de Javascript dans les navigateurs web.
Par ailleurs si, côté serveur, l’API change cela suppose qu’il faille renvoyer un nouveau “code on demand” vers l’ensemble des clients. C’est ce que soulignait récemment Léonard Richardson (le co-auteur de RESTful Web Services), dans sa conférence “How to Follow Instructions ? “, en rappelant une corrélation forte entre l’utilisation du “code on demand” et la faiblesse hypermedia des messages. Ce que l’on pourrait formuler de la manière suivante : plus le message est brut (sans hyperliens), plus le client doit être intelligent.
On peut donc continuer à faire du RESTful avec le “code on demand” mais beaucoup moins d’API ayant l’hypermedia comme moteur du changement des états applicatifs (HATEOAS). Le transfert de données brutes avec l’intelligence des données quelque part dans le code a la vie dure, comme l’illustre ces trois slides utilisé par Léonard Richardson dans la conférence citée précédemment :
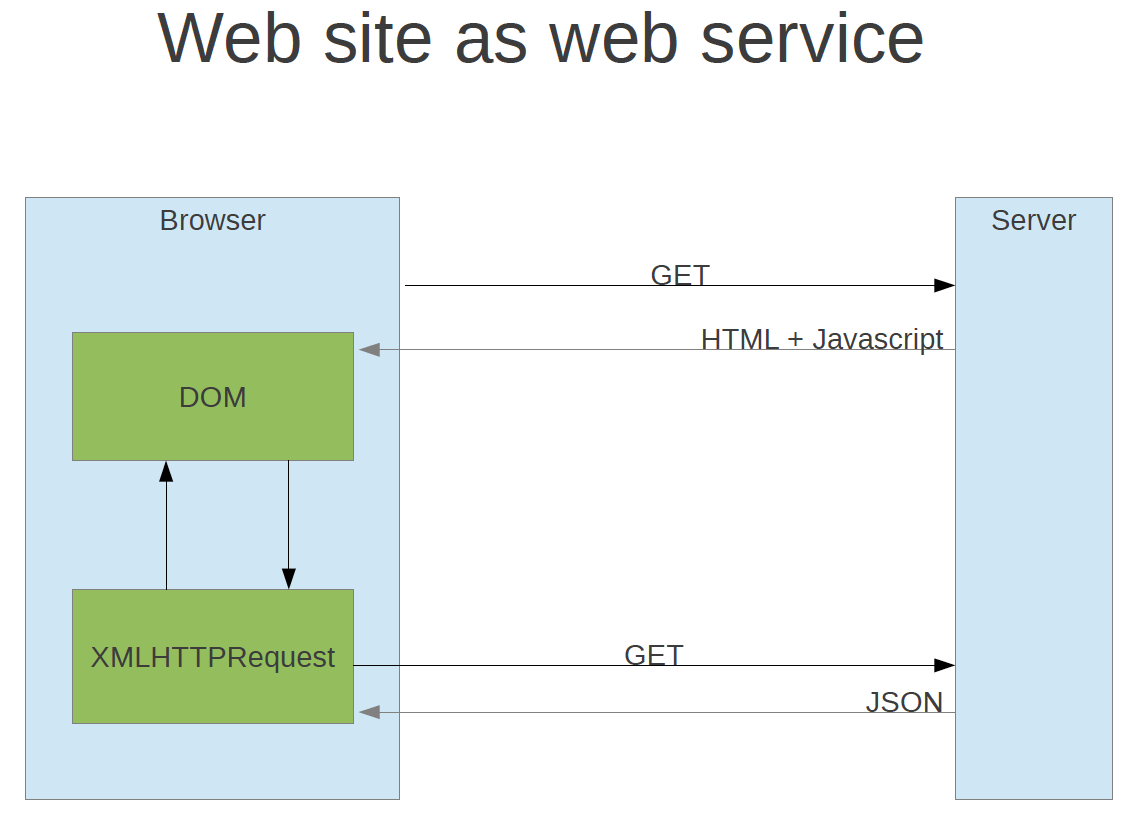


Le “code on demand“ est devenu la chambre de compensation de tous les manques d’hypermedia dans les messages, et celle-ci est bien remplie avec JSON !

Laisser un commentaire