Web APIs 101

Les démarches autour des “WAPIs” (Web Application Programming Interfaces) sont éminament bifaces : à la fois technologiques et business.
Les organisations qui réussissent le mieux à conjuguer ces deux aspects vous diront que leur API Web, c’est leur produit, ou leur service. Sous-entendu : c’est leur coeur de métier.
Ce sont des industriels qui opèrent sur le web, des compagnies pour lesquelles le web n’est pas qu’une technologie de publication et d’affichage de documents.
A partir de l’infrastructure de transport d’internet ils opèrent des transferts qui sont des jeux d’écritures à distance et à la vitesse de la lumière.
Être présent sur le web n’est pas opérer sur le web
Avoir une stratégie en matières d’API c’est nécessairement avoir pris la décision d’opérer sur le web, et pas seulement d’y apparaître en se contentant de s’y afficher dans des logiques publicitaires (aussi bien au sens de promotion qu’au sens générique de rendu public). C’est précisément là que se joue l’enjeu des APIs.
Cet enjeu doit être compris et partagé aussi bien par les informaticiens qui les conçoivent et les opèrent que par les autres directions de l’entreprise. Mon propos s’adresse aux deux.
Être présent sur le web ne veut pas dire que l’on opère sur le web. Le web n’est pas une affaire restreinte au département communication & marketing ; si on veut y opérer, tous les regards doivent converger vers les APIs. Si un employé , par son travail, ne participe pas directement ou indirectement a l’amélioration de la capacité de l’entreprise à opérer sur le web, c’est qu’il y a un problème en matière de politique industrielle (mais aussi culturelle le cas échéant) de l’organisation concernée.

Je sais bien que ce dernier paragraphe peut choquer tant il fait penser à une forme de dictature du numérique. Il ne s’agit pourtant pas de pointer du doigt ceux qui ne veulent pas faire du numérique le coeur de leur activité, chacun fait ce qu’il peut et ce qu’il veut, mais dans la mesure où nous parlons ici d’une vision industrielle, ce n’est pas une option que de croire que les questions industrielles puissent se poser en dehors du numérique en réseau.
Dans tous les secteurs d’activité, des stratégie industrielles basées sur les APIs se mettent en place pour court-circuiter des activité par ailleurs existantes soit format non numérique et/ou non-automatisé (Banque, Assurance, Immobilier, Edition, Industries Culturelles, etc. Cf “There is an App for that”) soit sans s’interfacer avec le web comme plateforme. Ces nouvelles initatives opèrent sur le web là où leur “concurrents” historiques se contentent maladroitement d’y être présents.
Quand une entreprise (surtout si elle est en B2C) m’interroge sur sa “stratégie web”, je demande souvent la part du chiffre d’affaire qui est généré par des paiements automatiques en ligne effectués sans aucune médiation humaine ; si elle est insignifiante je réponds que leur stratégie l’est certainement aussi.
Interfaces invisibles et ubiquitaires
Si l’on devait utiliser une métaphore pour caractériser ce qu’est une API, je dirai qu’une API est un guichet automatique. Mais si la plupart des guichets automatiques que nous cotoyons sont des guichets à destination d’utilisateurs humains, celui ci est un guichet à destination de ces automates que sont les machines numériques en réseau.
Mais n’est ce pas tout simplement un site web ? C’est effectivement le même protocole que celui des sites web qui est utilisé pour les APIs Web, mais autant un site web est fait pour des lecteurs humains autant une API est faite pour faire dialoguer des logiciels entre eux.
Ce que l’oeil humain voit d’un site web n’est pas ce qu’un logiciel peut en voir.
La mise en page, les styles d’affigeage, la connaissance d’une langue, bref tout ce qui fait sens pour nous à la vue d’un document est très difficilement opérable par un logiciel.
On parle des APIs comme interfaces non-visuelles, pour bien marquer la différence avec les interfaces visuelles et/ou tactiles des IHM.
A l’heure de la multiplication des appareils bénéficiant d’un accès au web, la multiplication des canaux de distribution du numérique rend de plus en plus inconcevable, pour une organisation donnée, de développer elle-même toutes les applications sur tous les nouveaux supports. Serait-elle en mesure de le faire que son patrimoine numérique resterait toutefois cantonné à ses seules applications, or ce patrimoine doit aujourd’hui pouvoir aller au-delà des applications de l’entreprise :

Présenter les APIs comme des interfaces non-visuelles c’est aussi dire la difficulté d’en parler à un néophyte puisqu’il n’y a rien à voir ; c’est la raison pour laquelle l’enjeu des API peut facilement passer sous le radars des décideurs qui se contentent de demander une application pour iPhone, puis pour iPad, puis pour Androïd, puis pour Windows Phone, etc. Quand ce genre de demande s’accélère, c’est le signe qu’une démarche orientée API devient opportune.
L’alignement et stratégies de services
Ce qui se joue avec les APIs n’est pas quelque chose de radicalement nouveau, c’est en fait un même problème qui est en permanente évolution depuis au moins les 20 dernières années et qui s’exprime depuis les dix dernières années dans différents slogans : le eBusiness, l’entreprise étendue, les architectures de services(SOA), le web 2.0, à présent les APIs, demain l’Internet des Objets, etc.
Durant tout ce temps, le discours qui a prévalu était (et est toujours) l’injonction d’ “aligner l’IT sur le Business”. Il m’est personnellement arrivé de dire qu’il faudrait aussi parfois que le Business s’aligne sur l’IT. Quoiqu’il en soit, la question du couplage des deux est une question qui devient permanente et lancinante. Cela se traduit concrètement par des démarches qui packagent l’IT dans une prestation de service – on parle de centre de service, corrélât d’une architecture de service – pour pouvoir mieux mesurer son efficience, et éventuellement la mettre en concurrence externe. Je me méfie de ces démarches parce que bien souvent elles affichent une politique du chiffre qui masque une cruelle absence de politique industrielle.
Anthropologie de l’adoption du web
D’un point de vue beaucoup plus général, voire anthropologique, nous dirons que l’humanité est entrée depuis le siècle dernier dans une période qui consiste à faire parler les objets technologiques entre eux. Après avoir appris à nous parler et à échanger à travers le numérique en réseau, grâce aux technologies relationnelles, nous cherchons à présentant à aller plus loin dans le dialogue entre les objets et les machines.
Dans ce contexte d’écritures automatisées généralisées, la question est à présent la même pour tout le monde, organisations et particuliers : comment vivre avec les automates ?

Dans une société automatisée, celui qui ne maîtrise pas ses propres capacités d’automatisation risque soit d’être exclu du périmètre industriel soit de devenir lui-même le serviteur de ceux qui auront mieux réussi que lui en lui imposant ses logiciels et ses algorithmes. De fort enjeux de dépendance et d’autonomie se posent comme nous le montre le devenir des industries culturelles dont l’affaire de la Lex Google en est une manifestation .
Tout comme la question n’est pas d’être présent sur le web mais d’opérer sur le web, l’enjeu pour une organisation n’est pas de s’adapter au web (prendre sur soi, comme un fardeau) mais d’adopter le web (le faire sien, en faire son affaire).
Qu’est ce que publier une interface ?
Il y a certainement de multiples manières d’aborder la question des APIs, j’en présente ici une qui met l’emphase sur la question des interfaces.
Une interface est la couche limite entre deux éléments, deux milieux, par laquelle ont lieu des échanges et des interactions. L’interface désigne ainsi ce que chaque milieu a besoin de connaître de l’autre pour que le couplage fonctionne correctement.
En informatique et en électronique, une interface est un dispositif qui permet des échanges et interactions entre différents composants. Une interface homme-machine permet des échanges entre un humain et une machine. Une interface de programmation permet des échanges entre plusieurs logiciels. Il y a plusieurs types d’interfaces en matière numérique que Pierre Jarillon a présenté de la manière suivante :
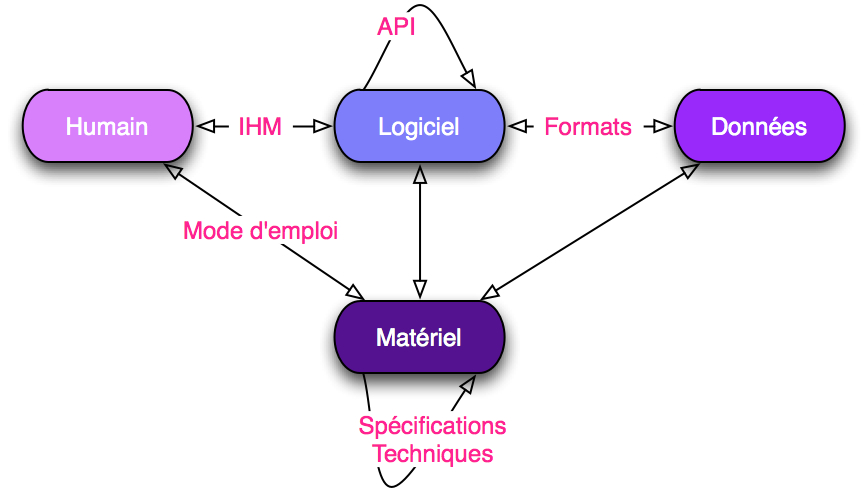
Ce petit schéma à le mérite de préciser de quoi on parle avec la publication des interfaces : si donc je publie un mode d’emploi, cela revient publier une interface, pareil si je publie des spécifications techniques, ou des normes concernant mes formats de données . Ce dont nous parlons ici c’est de la publication des interfaces logicielles sur le web.
En réalité, la situation n’est pas aussi tranchée. En effet, une démarche de publication des APIs s’accompagne toujours de publications pour les humains qui documentent le mode d’emploi des API, on documente également le format des données accessibles via les APIs.
Il y a toujours le graal d’avoir des APIs web qui pourraient se passer de documentation et pourraient se suffire à elles mêmes (ce qui passera par une meilleure mise en oeuvre de ce que Fielding appelle HATEOAS), mais personne n’envisage actuellement d’avoir une stratégie en matière d’API qui fasse l’économie d’une promotion et d’un accompagnement par des hommes et de la documentation.
Publier des interfaces n’est pas publier des données, même si cela revient indirectement à publier des données (cf DataCulture et ApiCulture). On a beaucoup parlé de publication ces dernières années : publication de documents, publication de code source et publication de données, quoi de plus normal quand on se rappelle que le web est une technologie de publication. Mais parler de publication d’interfaces, c’est relativement inédit. C’est certainement ce caractère novateur qui peut rendre difficile la compréhension des enjeux autour des APIs.
Publier comment et avec quelles attentes?
Tout d’abord c’est une publication automatisée, ensuite c’est une publication maîtrisée, enfin c’est une publication tracée , c’est la raison pour laquelle une API est avant tout un contrat ( qui doit être un contrat de confiance, c’est la raison pour laquelle les APIs relèvent aussi des technologies de confiance).
Qu’espérer d’une démarche de publication d’interfaces logicielles ?
- En interne : automatiser des taches ingrates et consommatrices de temps pour accéder à des données et/ou consolider des données. Avoir une vision transversale dans des tableaux de bords (consulter des états trans-applicatifs de processus) ;
- Avec les partenaires : automatiser des échanges de données (web intégration);
- Avec les clients : partager ou mutualiser une partie du système d’information ;
- Avec une OpenAPI (API ouverte au public) : développement d’applications présentant les données de l’entreprise (par exemple son catalogue de services ou de produits…) ;
En effet, sur le nombre d’APIs existantes, le site Programable Web rappelle fréquemment que l’immense majorité sont des APIs internes et privées malgré la croissance exponentielles des APIs publiques :

Pourquoi le design d’une API se fait-il “à l’aveugle ?”
Deux parties prenantes, chacune propriétaire d’une application, peuvent s’entendre pour que leurs applications respectives s’intègrent en s’interfaçant, c’est à dire en échangeant automatiquement des données entre elles. Avons-nous là une démarche de type API ? Et à chaque fois que plusieurs applications s’échangent des données diront nous qu’il y a l’utilisation d’API ?
La réponse est non. Même si deux applications, dans un même système d’information, s’échangent des données en utilisant le protocole HTTP on parlera d’abord de services web (qui peut être la mise en oeuvre d’une architecture de service) mais pas d’API. La frontière entre les deux est si subtile que même du côté de Wikipedia il y a des débats pour savoir si l’entrée “Web API” et l’entrée “Service Web” devraient être fusionnées.
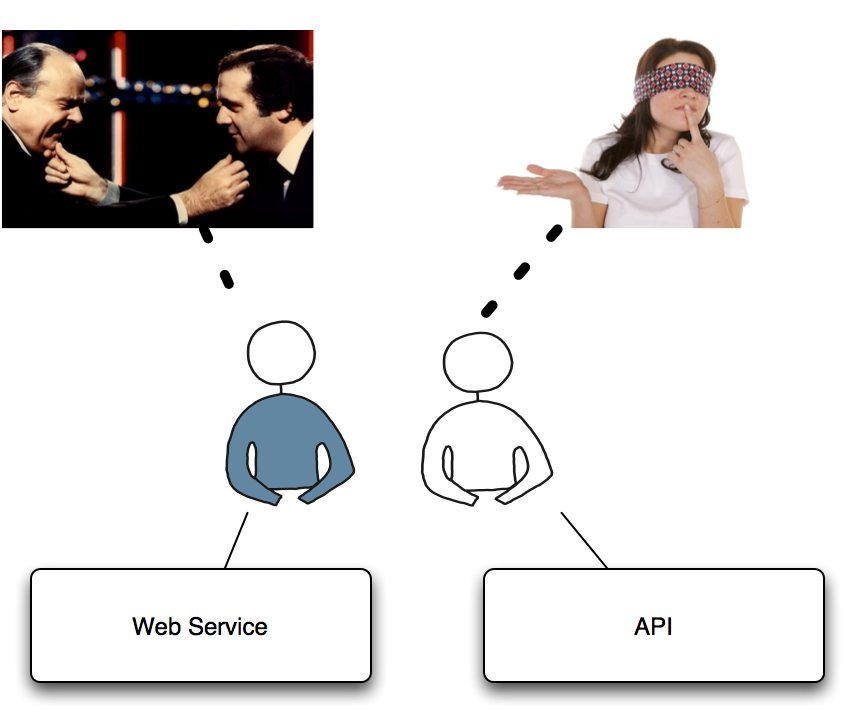
Pour différencier les deux démarches (car il s’agit ici plus d’un état d’esprit qui va ensuite se concrétiser dans des différences de conception et d’architecture) je dirai la chose suivante :
- dans la logique de faire communiquer deux applications entre elles, la démarche de conception du mécanisme d’échange est partagée par les deux responsables des applications. On construit un pont en connaissant les deux rives qui serviront de fondation ; on tire un trait entre deux éléments connus, et ce sont généralement les même développeurs qui ont accès aux deux logiciels qui doivent être intégrés.
- avec une démarche orientée API, contrairement à l’approche intégration à base de service web, on ne connaît pas l’autre rive. On construit seulement une partie de l’ouvrage (la partie côté serveur) sans connaître les logiciels (côté client) qui verront le jour et compléteront ainsi l’ouvrage.
On comprend aisément que concevoir un système d’échange de message entre deux application données n’a pas les mêmes contraintes qu’un système de message dont on ne connaît que l’émetteur et pas le récepteur.
Proposer une API, c’est proposer un service rendu par un serveur dont on ne connaît pas l’usage qui sera fait par le client. C’est donc résoudre une équation plutôt que construire un pont, pour reprendre l’analogie plus haut.
Aussi, quand on veut construire un service sans connaître les clients il faut oublier ce que fera le client des données accessibles via l’API. Là où une architecture de services web organise les échanges entre le serveur et le client en connaissance de cause, c’est à dire en comprenant les enjeux côté serveur ET côté client, la conception d’une API doit se concentrer sur le mécanisme des messages échangés entre les deux, sans préjuger des utilisations de ces messages que ce soit côté serveur ou côté client.
Publier pour qui ? La figure du développeur.
Quelle que soit l’entité qui utilisera l’API publiée par une organisation (interne clients, partenaires, public), le premier destinataire est le développeur. C’est d’abord pour lui que tout le travail de conception et de publication de l’API a été fait. C’est au développeur que revient la décision d’utiliser ou de ne pas utiliser une API ; si le développeur ne s’empare pas de l’API, celle-ci reste lettre morte, et tous les efforts n’auront servis à rien.

En partie, oui. Mais il faut distinguer des cas de figures différents, selon le mode de publication et de diffusion des APIs. Si l’on reste dans le périmètre de l’entreprise qui décide de publier une API, la situation n’est pas la même qu’avec une API publique, ouverte à tous. En interne, on ne publie des APIs qu’en sachant déjà qu’il y aura des cas d’usage et donc des clients/logiciels qui feront appel à l’API. La situation devient moins prévisible dans le cas d’un API à destination de partenaires ou de clients, ils peuvent ne pas être convaincu par l’intérêt de l’API ou ne pas être satisfaits par la qualité de l’API et décider qu’ils ne l’utiliseront pas.
Par où commencer ?
J’aime bien les approches qualitatives, mais en l’occurrence il faut travailler avec des données et des faits, il ne s’agit pas de s’imaginer plus intelligent que tout le monde et prétendre savoir quelles sont les données qui peuvent être valorisées à l’extérieur de leur logiciel en étant accessible via l’API.
Si l’on se place dans une démarche d’APIs internes, faites donc un sondage web auprès des employés concernés avec une question simple et précise : de quelle données avez vous besoin et avec quelle fréquence ? Quelles données vous sont demandées, et avec quelle fréquence ?

Il y a dans cette démarche (démarche orientée ressources)de quoi poser des bases solides pour constituer une démarche d’API en interne, qui pourra s’enrichir avec les partenaires, les clients et, pourquoi pas, avec des APIs Publiques si l’on veut opérer de manière ubiquitaire.
En ce qui me concerne, je considère qu’il faut concevoir des API internes, dans la mesure du possible, comme si elles étaient publiques, cela permet une meilleure maintenabilité de l’API malgré les évolutions des applications interfacées. Quoiqu’il en soit, les questions de conception technique/business des APIs ne font alors que commencer.
Bonjour Christian,
je suis parfaitement en phase avec votre article. Je trouve intéressant d’insister sur la notion de mise à disposition de données sans préjuger de leur utilisation par les tiers. A travers un court article que j’ai rédigé pour structurer mes idées (http://contribuez.wordpress.com/2012/08/21/le-marche-des-api/ ) j’essaye de mieux appréhender l’émergence rapide de cette économie reposant sur les api web, mais la vitesse d’évolution des modèles et des technologies rend l’entreprise particulièrement complexe. Je suis en charge d’sfr api et je ne peux que confirmer la difficulté qu’il y a à faire accepter ce type de technologie à des profils non développeurs surtout lorsque ça n’est pas dans l’adn de l’entreprise. Ce n’est peut être pas un hasard si les champion de l’exposition d’api sont souvent des entreprises diriger par des anciens développeurs (Amazon étant peut être le contre exemple). Je rejoins parfaitement le point sur la confiance et j’ajouterais pour faire le lien avec ars industrialis que les open api sont probablement de puissant leviers pour l’économie de la contribution.
Hervé
[Reply]
[…] pour la conception des APIs Hypermédiasby Christian on 14 novembre, 2012L’article sur Web APIs 101 se terminait en disant que les démarches de conception d’APIs pouvait alors seulement commencer. […]

Bonjour Christian,
La notion de service n’est pas défunte, il me semblerait dommage de la restreindre aux premières pratiques en entreprise qui ont eues visiblement du mal à s’émanciper des composants distribués.
Vu sous un angle logiciel, on peut dire que le service s’émancipe du composant de la même façon que le composant vis-à-vis de l’objet.
L’orienté service s’intéresse à la fourniture d’une fonctionnalité par tiers et à la différence des composants distribués, il pousse cette logique beaucoup plus loin puisque c’est son postulat de départ. L’objectif est ici d’interagir avec des tiers aussi divers et indépendants que possibles, ce qui impose de minimiser le nombre d’hypothèses devant être partagées pour pouvoir interagir. Cela se définit comme la minimisation du couplage. Effectivement, lorsqu’un service d’entreprise est conçu en connaissant le comportement de son consommateur, il introduit un couplage fort qui va dans le sens contraire de cet objectif. Selon moi, l’orienté service s’apparente naturellement à une logique B2C : elle doit
faciliter autant que possible la tâche de son client, le consommateur, et s’adresser à un public aussi large que possible pour pouvoir être réutilisée. Bien entendu, l’accès peut être restreint pour des raisons de sécurité mais pas pour des raisons techniques.
Le courant WebAPI semble être plus soucieux de ce type d’enjeu lorsqu’il conçoit ses interfaces (descriptions de services), qu’il réserve
pour l’instant à des développeurs humains. Il semble intéressant d’augmenter ces descriptions à un niveau sémantique interprétable par les machines, ce qui pourrait être une façon de mettre en oeuvre
le principe HATEOAS cher à R. Fielding et au cœur de REST (http://roy.gbiv.com/untangled/2008/rest-apis-must-be-hypertext-driven). À ce sujet, je trouve très intéressante la proposition récente http://restdesc.org/ basée sur HTTP Link, HTTP OPTIONS et N3Logic.
Ces descriptions sémantiques sont un élément de base important pour l’automatisation de la chaîne, qui a minima concerne la découverte des services (à la HATEOAS) mais peut aussi
s’intéresser à la sélection et à la composition automatique par planification. Le besoin de ces fonctionnalités ne fait certes pas encore resentir au niveau aux systèmes d’information d’entreprise, mais il devient plus fort lorsqu’on s’intéresse à des objets mobiles communiquants. En effet, il serait souhaitable qu’ils puissent se découvrir et interagir entre eux automatiquement lorsqu’ils sont à proximité, sans qu’un développeur n’ait besoin de lire la documentation de chaque nouvel arrivant.
[Reply]