« Web of Data » n’est pas « Data on the Web »
Pour positionner le web sémantique, ses principaux promoteurs, dont Tim Berners Lee, parlent de plus en plus de « Web of Data ».
Mais quoi ! N’y a t il pas déjà des données sur le web ? Certes, mais ces données sont propulsées et affichées à partir de bases de données dont l’accès est verrouillé par des applications, fussent-elles des « applications web » avec des API ouvertes.
On est encore dans une compréhension du web dans son essence cinématographique : les données sont projetées sur la toile.

Et, de fait, le web est un beau spectacle où chacun peut participer en projetant ses oeuvres (textes ou multimedia). Mais dans ce processus cinématographique, c’est l’oeuvre qui fait sens, je veux dire par là que chaque auteur définit ses unités documentaires. Par exemple je n’ai pas accès aux rushes utilisés pour le montage d’un court métrage. Si je veux réutiliser ce documentaire, je devrais repartir de l’unité documentaire projetée/diffusée par l’auteur.
Alors oui, le web d’aujourd’hui est un web dans lequel il y a des data, mais ces « Data on the Web » n’en constituent pas pour autant un « Web of Data ».
La nuance est de taille, mais où se situe-t-elle en dehors du jeu grammatical d’inversion des sujets ?
Nova Spivack est une des personnes les plus affûtées lorsqu’il s’agit de comprendre l’évolution du web et le rôle que le web sémantique y joue. Il n’est pas peut être pas l’auteur de l’expression (Danny Ayers ?), mais en parlant d’ « hyperdata » il met le doigt sur quelque chose d’important.
Qu’est ce que l’hyperdata ?
Hyperdata est au web sémantique ce que l’hypertext est au web d’hier et d’aujourd’hui.
Quoi de neuf depuis la vision de Ted Nelson, « inventeur » de l’hypertext, dans ce dessin de 1963 ? :
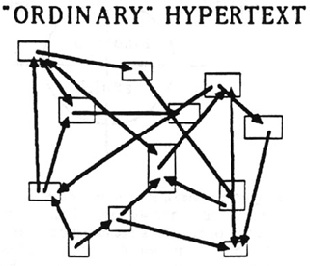
Chacun reconnaîtra dans l’esquisse de Ted Nelson une forte similarité avec le schéma d’un graphe RDF.
Il y a pourtant deux choses qui changent lorsqu’on passe de l’hypertext à l’hyperdata :
- d’abord les liens ne se font pas entre des documents mais entre des data : le document est là pour l’oeil humain (vive le surf), alors que les data sont là pour être exploitées par les machines.
- ensuite les liens deviennent typés, on peut les définir et aller au-delà de la simple liaison indéfinie ou implicite (définie par le contenu du document source ou les précisions de l’auteur)
Le terme d’hyperdata a donc le mérite d’éclairer la différence entre les « data on the web » et le « web of data » : dans un cas on a l’hypertext et dans l’autre l’hyperdata.
Il faut pourtant aller encore plus loin en précisant que l’hyperdata n’a de sens, de facto, qu’en tant qu’hypermetadata. Et nous pouvons enfin poser l’égalité de sens et d’intention suivante :
hyperdata => hypermetadata = Resource Description Framework.
L’enjeu du web sémantique en tant qu’hypermetadata est double :
- sur la partie « front office » du web : pouvoir afficher (mais comme on n’est plus dans une conception cinématographique il vaudrait mieux dire « générer » qu’afficher) des documents non pas simplement « à la demande » mais construits et constitués pour et par la requête. C’est à dire des documents qui ne préexistent pas dans une base de données à partir de laquelle ils seraient simplement stockés pour être affichés tel quels. On pense bien évidemment aux mashups qui produisent des documents inédits, à la demande, et qui sont les prémices de ce que peut apporter le web sémantique aux utilisateurs. En ce sens, les projets du programme SIMILE font toucher du doigt ce que l’on pourrait faire avec des données aux normes du web sémantique (même s’ils ne s’appuient pas, ou peu, sur des données aux normes du web sémantique).
- sur la partie backoffice, il s’agit de refondre les modalités de stockage des data sur le Web (passage d’un web de documents à un web de données) en utilisant un modèle de données basé sur le principe de l’hypermetadata qui se prête à une plus grande structuration et donc à des modes de requêtage (SPARQL) offrant la possibilité de se passer d’un filtre applicatif qui encapsulerait les données :
Une question demeure que je ne peux éluder, sans pour autant y répondre avec exhaustivité : les normes du web sémantique sont-elles faites pour le Web ou pour les systèmes d’information des entreprises ?
Pour éclairer cette question, disons que ce qui est fait « pour le Web », est fait pour n’importe qui, n’importe quand, et de n’importe où. Or, dans l’entreprise les usages sont définis dans des spécifications fonctionnelles où l’on détaille avec précision les scénarii d’usage : qui va l’utiliser, quand, comment et quels sont les processus séquentiels qui seront portés par l’application.
Parti comme çà, et si de plus l’entreprise travaille exclusivement avec des SSI et des éditeurs de progiciels, aucune chance de voir émerger le web sémantique dans cette l’entreprise.
Aussi, à part quelques rares exceptions, le web sémantique ne sera pas porté par des décisions émanant d’entreprises et pour leur usage interne. Il le sera par des solutions web – en mode SaaS – qui adressent des enjeux d’interopératbilité à une échelle mondiale (en intension et en extension).
C’est dans les approches collaboratives (collaboratif signifiant « je travaille pour ET avec quelqu’un d’autre sur des données partagées, et non pas simplement « j’échange des données » qui est la conception eBusiness) mais aussi dans la gestion de catalogues que les normes du web sémantique apportent des solutions naturelles.
Entendez moi bien, je crois que tout peut-être adressé avec les normes du web sémantique ; simplement il est des domaines, ou des sujets, pour lesquels le choix des normes du web sémantique n’est pas déterminant, ni critique.
Ainsi, si une entreprise se demande si elle doit basculer certaines de ses données en RDF, elle devra se poser la question :
« Mes données ont-elles un sens à l’échelle du web ? »
C’est à dire également :
« Ai-je besoin d’une politique (industrielle, commerciale, institutionnelle ou culturelle) de présence numérique de mes données à une large échelle ? »
Pour prolonger cette discussion avec mes préoccupation autour du SaaS (Software as a Service), je précise ma vision dans laquelle les normes du web sémantiques vont dans le sens d’une montée en puissance (commerciale, économique et fonctionnelle) des offres SaaS.
Ce sont en effet les acteurs du SaaS, et plus précisément aux acteurs proposant des plate-formes SaaS, qui offrent aux normes du Web Sémantique un milieu propice à l’industrialisation du « web of data ».
Nous rentrons dans une phase de transition ou des solutions disparates de SaaS peuvent être choisies et utilisées les unes indépendamment des autres, mais viendra pour les entreprises – tout comme pour les particuliers – le temps du choix d’une plate-forme SaaS : Plateform as a Service (PAAS).
Cela peut paraître énigmatique, mais j’en arrive à la conclusion que le trésor (thesaurus) des systèmes d’information des entreprises doit être en dehors du système d’information : sur le « Web of Data ». Car ce n’est pas parce que l’on parle d’ « internet software » ou de « cloud computing » qu’il faut comprendre cette tendance comme une sorte de « fog of war » dont il faudrait se méfier (où sont mes données, est-ce sécurisé, etc.)
Aucune entreprise ne me fera croire qu’elle maîtrise son système d’information, encore moins celles qui investissent dans le SOA, et que par comparaison le passage au SaaS est flou et risqué. En guise de réponse, et de conclusion de cette note, je paraphraserai Bob Warfield en rappelant que :
» il ne faut jamais monter l’escalier d’un immeuble qui menace de s’écrouler, mais prendre l’issue de sortie ».
Pas mal ton idée de « web of virus » mais ce n’est pas ça ! 😉 En fait, il faut bien comprendre que les traitements ne seront pas contenus dans les objets, ces derniers ne feront que définir un ensemble d’actions possibles, avec la liberté pour l’utilisateur de choisir lui-même les services web qui seront en charge des traitements. Autrement dit, le web sémantique vise à normaliser les données et le web orienté objet ajoute la normalisation des services. Je suis justement en train d’écrire quelque chose sur le sujet, suite sur mon blog donc. 😉
[Reply]
Et c’est pour ça que votre fille est muette.
ça fait tellement plus chic de palrler d’hyperdata plutôt, tout simplement, de métadonnées. réinventons, réinventons.
Peer
[Reply]
[…] avec le Web 3.0 et le Semantic Web c’est le “web of data” qui se constitue, et pas seulement des datas sur le web. […]
Il est toujours utile de revenir sur des billets et étudier comment notre approche d’une question peut changer ou, du moins, évoluer. La preuve avec ton billet.
Je suis complètement d’accord avec ta position. Il est clair que les éditeurs SAAS en exposant les données de l’entreprise sur le Web trouve dans les technologies du Web sémantique un moyen efficace (efficient ?) pour accéder et relier les données des entreprises entre les différents services. Les technologies du Web sémantique apportent à la fois un modèle (RDF) et une API unique (SPARQL) quelque soit la structure des données ce qui en facilite l’interopérabilité et la ré-utilisation.
Néanmoins, il me semble qu’il existe un cas pour lequel les technologies du Web sémantique peuvent trouver une place idéale dans le système d’information d’une entreprise. Dans ton billet, tu précises que les entreprises définissent leurs usages dans les spécifications fonctionnelles. Or, avec l’entrée du Web 2.0 dans les SI legacy, les usages qu’ils offrent doivent évoluer rapidement selon les besoins des utilisateurs. C’est une des caractéristiques du Web 2.0. Il est alors difficile de prévoir les futurs usages.
Si les entreprises ne veulent pas refaire tout leur système d’information tous les quatre matins, il leur faudra effectuer la modélisation et la structuration des données de manière indépendante des usages, et c’est précisément ce qu’offre les technologies du Web sémantique et c’est bien la limite des architectures SOA et des API actuels, puisqu’ils offrent un moyen d’accéder aux données et à leurs structures en fonction d’usages précis et pré-déterminées.
Evidemment, tout n’est pas résolu, simplement l’évolution du système ne se situera plus au niveau de la structuration des données, ni sur l’API qui permet d’y accéder, mais simplement au niveau du programme qui exploite les données.
Maintenant, cerise sur le gâteau : dans la mesure où on sépare la data du software qui l’exploite, ne manque-t-il pas aujourd’hui un acteur SAAS qui gère la data et la mette à disposition des acteurs qui exploitent la data ? En gros, une nouvelle couche apparaît entre Amazon et son cloud computing et Salesforce avec ses solutions, non ?
Qu’en penses-tu ?
[Reply]
I lover your articles there awesome.
[Reply]

Merci Christian pour ce formidable billet ! Cependant, j’ai un peu de mal à adhérer à la vision que tu présentes même si, j’en suis bien conscient, elle est partagée par la grande majorité des acteurs du web. Tu parles de données d’un côté, le « Web of Data », et de services de l’autre (SaaS) alors qu’il serait possible, je crois, de réunir les deux mondes pour aller vers un « Web of Object » ou Web Orienté Objet. C’est l’idée d’un web permettant de distribuer des objets ou « machines dématérialisées ». Par exemple, si je propage un objet « texte » dans mon réseau social, j’aimerais bien avoir la possibilité d’indiquer un certain nombre de fonctions possibles sur cet objet : modification (wiki), traduction, gestion des tags, fonctions « commentaire », « vote », « achat » ou « don »…
[Reply]